

Как вы обеспечиваете, чтобы ваши решения на основе ИИ работали так, как вы ожидаете?
Краткое введение в оценку ИИ
Генеративный ИИ (GenAI) стремительно развивается, и теперь это уже не просто забавные чат-боты или генерация впечатляющих изображений. В 2025 году основное внимание будет уделяться превращению шумихи вокруг ИИ в реальную ценность. Компании по всему миру ищут способы интегрировать и использовать GenAI в своих продуктах и операциях, чтобы лучше обслуживать пользователей, повышать эффективность, поддерживать конкурентоспособность и стимулировать рост. Благодаря API и предварительно обученным моделям от ведущих поставщиков интеграция GenAI кажется проще, чем когда-либо. Но вот в чем суть вопроса: Простота интеграции не означает, что решения на основе ИИ будут работать так, как задумано, после развертывания.

Прогностические модели на самом деле не новы: люди уже много лет занимаются прогнозированием событий, официально начав со статистики. Однако, GenAI производит революцию в области прогнозирования по многим причинам.:
- Вам не нужно обучать собственную модель или быть специалистом по обработке данных, чтобы создавать решения на основе ИИ.
- Теперь искусственный интеллект легко использовать через чат-интерфейсы и легко интегрировать через API.
- Освобождение многих вещей, которые раньше было невозможно сделать или было очень сложно сделать.
Все эти вещи делают GenAI — это очень интересно, но и рискованно.. В отличие от традиционного программного обеспечения — или даже классического машинного обучения — GenAI предлагает новый уровень непредсказуемости. Вы не реализуете детерминированную логику, вы используете модель, обученную на огромных объемах данных, надеясь, что она отреагирует так, как нужно. Так как же нам узнать, делает ли система ИИ то, что мы от нее хотим? Как узнать, готов ли он к запуску? Ответ — это оценка, концепция, которую мы рассмотрим в этой статье:
- Почему системы Genai нельзя тестировать так же, как традиционное программное обеспечение или даже классическое машинное обучение (ML)
- Почему рейтинги необходимы для понимания качества вашей системы ИИ, а не являются дополнительными (если только вы не любите сюрпризы)
- Различные виды оценок и методики их применения на практике
Независимо от того, являетесь ли вы менеджером по продукту, инженером или любым другим человеком, работающим с ИИ или интересующимся им, я надеюсь, что эта статья поможет вам понять, как критически относиться к качеству систем ИИ (и почему оценки необходимы для достижения этого качества!).
Генеративный ИИ невозможно протестировать так же, как традиционное программное обеспечение или даже как классическое машинное обучение.
В традиционной разработке программного обеспеченияСистемы следуют детерминированной логике: Если произойдет X, то произойдет Y. - всегда. Если только что-то не пойдет не так с вашей платформой или вы не допустите ошибку в своем коде... именно поэтому мы добавляем тесты, мониторинг и оповещения. Модульные тесты используются для проверки небольших блоков кода, интеграционные тесты — для обеспечения совместной работы компонентов, а мониторинг — для обнаружения неисправностей в процессе производства. Традиционное тестирование программного обеспечения похоже на проверку работы калькулятора. Вы вводите 2 + 2 и ожидаете 4. Ясно и неизбежно, либо правда, либо ложь.
Однако машинное обучение и искусственный интеллект вносят неопределенность и вероятность. Вместо того чтобы явно определять поведение с помощью правил, мы обучаем модели изучать закономерности на основе данных. В ИИ, если происходит событие X, выходным значением больше не является жестко заданное значение Y, а прогноз с некоторой степенью вероятности, основанный на том, чему модель научилась во время обучения.. Это может быть очень эффективным, но также вносит неопределенность: идентичные входные данные могут со временем давать разные выходные данные, правдоподобные выходные данные могут на самом деле быть неверными, а в редких сценариях может возникнуть неожиданное поведение…
Это делает традиционные методы тестирования недостаточными, а иногда даже невозможными. Пример с калькулятором близок к попытке оценить успеваемость студента на открытом экзамене. Правильный ли ответ дан для каждого вопроса и множества возможных способов ответа на него? Выше ли уровень знаний, которым должен обладать студент? Студент все выдумал, но звучит очень убедительно? Так же, как ответы на экзамене, Системы ИИ можно оценить, но им нужен более общий и гибкий способ адаптации к различным входным данным, контекстам и вариантам использования. (или типы тестов).
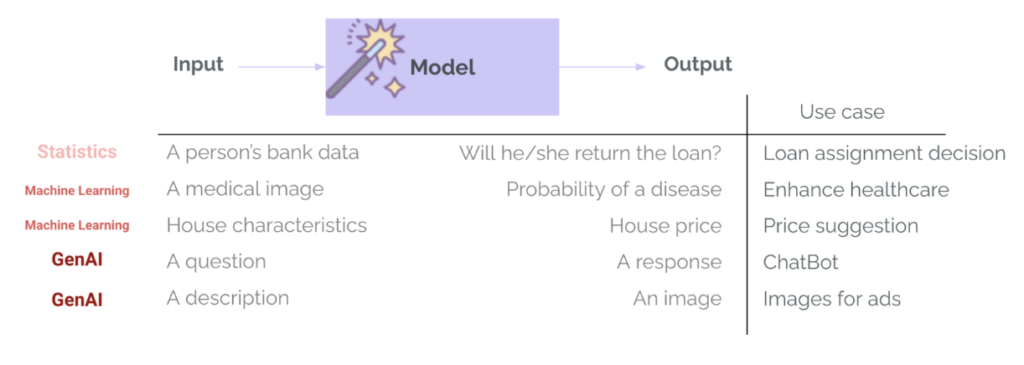
В машинное обучение Традиционно (ML) оценки уже являются устоявшейся частью жизненного цикла проекта.. Обучение модели для узкой задачи, такой как одобрение кредита или выявление заболеваний, всегда включает этап оценки с использованием таких показателей, как точность, полнота, среднеквадратичное отклонение, средняя ошибка… Это используется для измерения эффективности модели, для сравнения различных вариантов модели и для определения того, достаточно ли хороша модель для перехода к развертыванию. В GenAI ситуация обычно меняется: команды используют модели, которые уже обучены и прошли общую внутреннюю оценку поставщиком модели, а также публичные сравнительные тесты. Эти модели очень хороши для выполнения общих задач, таких как ответы на вопросы или составление электронных писем, и существует риск чрезмерного доверия к ним в нашем конкретном случае использования. Однако важно спросить: «Достаточно ли хорош этот замечательный шаблон для моего варианта использования?«Вот тут-то и нужна оценка». – Чтобы оценить, подходят ли прогнозы или генерации для конкретного варианта использования, контекста, входных данных и пользователей.

Есть еще одно важное различие между машинным обучением и GenAI: разнообразие и сложность выходных данных модели. Мы больше не возвращаем категории и вероятности (например, вероятность возврата клиентом кредита) или числа (например, ожидаемую цену дома на основе его характеристик). Системы GenAI могут возвращать множество типов выходных данных с различной длиной, тоном, содержанием и форматом. Аналогичным образом, эти модели больше не требуют строго структурированных и специфических входных данных, а, как правило, принимают практически любой тип входных данных — текст, изображения или даже аудио или видео. Поэтому оценка становится намного сложнее.
Почему оценки необходимы, а не являются необязательными (если вы не предпочитаете неприятные сюрпризы)
Оценки помогают вам определить, действительно ли ваша система ИИ работает так, как вы задумали. Ты этого хочешь, готова ли система к работе, и если да, то продолжает ли она работать так, как ожидалось. Ниже приведен анализ того, почему оценки важны:
- Оценка качества: Оценки предоставляют структурированный способ понять качество ваших прогнозов или результатов ИИ, а также то, как они будут интегрироваться в общую систему и вариант использования. Являются ли ответы точными? Полезный? Сплоченный? Связанный?
- Количественная оценка ошибок: Рейтинги помогают определить процент, типы и величину ошибок. Как часто возникают ошибки? Какие типы ошибок встречаются чаще всего (например, ложные срабатывания, галлюцинации, ошибки форматирования)?
- Снижение риска: Он помогает вам выявлять и предотвращать вредоносное или предвзятое поведение до того, как оно станет известно пользователям, защищая вашу компанию от репутационных рисков, этических проблем и потенциальных проблем с регулированием.
Генеративный ИИ со свободными отношениями ввода-вывода и генерацией длинных текстов делает оценки более релевантными и сложными. Когда дела идут плохо, они могут пойти очень плохо. Мы все видели заголовки о чат-ботах, дающих опасные советы, моделях, генерирующих предвзятый контент, и инструментах искусственного интеллекта, выдающих ложные факты.
ИИ никогда не будет идеальным, но с помощью оценок вы можете снизить риск возникновения неловкой ситуации, которая может стоить вам денег, авторитета или вирусного момента в Twitter.
Как вы определяете стратегию оценки ИИ?

Итак, как мы определяем рейтинги нашего ИИ? Универсального метода оценки не существует. Оценки зависят от конкретного варианта использования и должны соответствовать конкретным целям вашего приложения ИИ. Например, если вы создаете поисковую систему, вас может волновать релевантность результатов. Если это чат-бот, вас наверняка волнуют полезность и безопасность. Если информация засекречена, вас, скорее всего, будут волновать точность и правильность. Для систем, включающих несколько этапов (например, система ИИ, которая выполняет поиск, расставляет приоритеты по результатам, а затем генерирует ответ), часто необходимо оценивать каждый этап. Идея здесь заключается в том, чтобы измерить, помогает ли каждый шаг достичь общей метрики успеха (и на основе этого понять, на чем следует сосредоточить итерации и улучшения).
К общим областям оценки относятся:
- Правильность и галлюцинации: Являются ли полученные результаты реалистично точными? Генерирует ли система неверную информацию или галлюцинации?
- Релевантность: Соответствует ли контент запросу пользователя или предоставленному контексту?
- безопасность, предвзятость и токсичность
- Формат: Вывод имеет ожидаемый формат (например, JSON, допустимый вызов функции)?
- Безопасность, предвзятость и токсичность: Генерирует ли система вредоносный, предвзятый или токсичный контент?
Метрики, специфичные для задачи. Например, в задачах классификации используются такие метрики, как точность и достоверность, в задачах резюмирования — ROUGE или BLEU, а в задачах генерации кода регулярных выражений и проверки безошибочного выполнения.
Как на самом деле рассчитываются оценки?
После того, как вы определились с тем, что хотите измерить, следующим шагом станет разработка тестовых случаев. Это будет набор примеров (чем больше, тем лучше, но всегда с учетом баланса стоимости и затрат), где у вас есть:
- Пример ввода:Реалистичное представление вашей системы после ее запуска в производство.
- Ожидаемый результат (Если применимо): Ключевой факт или пример желаемых результатов.
- Метод оценки: Механизм регистрации для оценки результата.
- Результат или успех/неудача: Расчетная метрика, которая оценивает ваш тестовый случай.
В зависимости от ваших потребностей, времени и бюджета существует несколько методов, которые вы можете использовать в качестве методов оценки:
- Инструменты статистической регистрации, такие как: BLEU, ROUGE и METEOR, или косинусная мера сходства между встраиваниями — хорошо подходит для сравнения сгенерированного текста с эталонным выводом.
- Традиционные метрики машинного обучения, такие как Точность, полнота и AUC — лучше всего подходят для классификации с маркированными данными.
- Большая языковая модель в качестве судьи (LLM-as-a-Judge) Используйте большую языковую модель для оценки выходных данных (например, «Правильный ли и полезный ли это ответ?“). Особенно полезно, когда неклассифицированные данные недоступны или при оценке открытой конструкции.
Оценки на основе кодов Используйте регулярные выражения, логические правила или реализацию тестовых случаев для проверки форматов.
Суть
Давайте разберем все на конкретном примере. Представьте, что вы создаете систему анализа настроений, которая поможет вашей службе поддержки клиентов расставить приоритеты при обработке входящих писем.
Цель состоит в том, чтобы гарантировать, что самые срочные или негативные сообщения получат более быстрые ответы, что позволит снизить разочарование, повысить удовлетворенность и сократить отток клиентов. Это относительно простой вариант использования, но даже в такой системе с ограниченной производительностью качество имеет значение: неверные прогнозы могут привести к случайной расстановке приоритетов в электронных письмах, а это означает, что ваша команда будет тратить время на систему, которая стоит денег.
Как же узнать, работает ли ваше решение так, как вам хотелось бы? Вы оцениваете. Вот несколько примеров того, что может иметь значение для оценки в этом конкретном случае использования:
- Проверка формата: Возвращаются ли выходные данные вызова большой языковой модели (LLM) для прогнозирования настроений в электронных письмах в ожидаемом формате JSON? Это можно оценить с помощью проверок на основе кода: регулярных выражений, проверки схемы и т. д.
- Точность классификации настроений: Правильно ли система классифицирует тональность в различных текстах — коротких, длинных и многоязычных? Это можно оценить с помощью данных, маркированных с использованием традиционных метрик машинного обучения (метрик МО) или, если метки недоступны, с использованием большой языковой модели (LLM) в качестве судьи.
После того как решение будет запущено, вам также захочется включить показатели, наиболее тесно связанные с конечным воздействием вашего решения.:
- Эффективность приоритизации: Действительно ли сотрудники службы поддержки направляют свои письма к самым важным? Соответствует ли расстановка приоритетов желаемому влиянию на бизнес?
- Окончательное влияние на бизнес: Сокращает ли эта система время отклика, уменьшает ли она отток клиентов и повышает ли она показатели удовлетворенности?
Оценки необходимы для того, чтобы гарантировать, что системы ИИ полезны, безопасны, ценны и готовы к использованию в производственных целях. Итак, независимо от того, работаете ли вы с простым классификатором или открытым чат-ботом, уделите время определению того, что означает «достаточно хорошо» (минимальное приемлемое качество), и постройте на его основе оценки для его измерения!
ссылки
[1] Вашему продукту ИИ нужны оценкиХамель Хусейн
[2] Метрики оценки LLM: Полное руководство по оценке LLM, Confident AI
[3] Оценка агентов ИИ, deeplearning.ai + Arize
Комментарии закрыты.