

Тайная внутренняя жизнь агентов ИИ: понимание того, как меняющееся поведение ИИ влияет на бизнес-риски
Часть 2 из серии статей о переосмыслении согласованности и безопасности ИИ в эпоху глубокого планирования.
Возможности и автономность искусственного интеллекта (ИИ) растут ускоренными темпами Агентный ИИ, что усугубляет проблему согласования ИИ. Эти быстрые изменения требуют новых способов обеспечения соответствия поведения агентов ИИ намерениям их создателей-людей и общественным нормам. Однако разработчикам и специалистам по обработке данных сначала необходимо понять тонкости поведения ИИ-агентов, прежде чем они смогут управлять системой и контролировать ее. Агентный ИИ — это не большая языковая модель (LLM) вашего отца — пограничные LLM имели фиксированную, одноразовую функцию ввода и вывода. Добавлена запись Рассуждения и расчеты во время теста (TTC) Измерение времени, которое привело к развитию LLM в современные ситуационно-ориентированные агентские системы, способные планировать и разрабатывать стратегии.

Безопасность ИИ переходит от обнаружения явного поведения, такого как предоставление инструкций по созданию бомбы или проявление нежелательной предвзятости, к пониманию того, как эти сложные агентские системы теперь могут планировать и реализовывать долгосрочные скрытые стратегии. Целеустремленный ИИ-агент будет собирать ресурсы и выполнять логические шаги для достижения своих целей, иногда тревожным образом, который противоречит замыслу разработчиков. Это кардинально меняет ситуацию с задачами, стоящими перед ответственным ИИ. Кроме того, для некоторых систем ИИ-агентов поведение в первый день не будет таким же, как в сотый день, поскольку ИИ продолжает развиваться после первоначального развертывания в ходе реального опыта. Этот новый уровень сложности требует новых подходов к безопасности и выравниванию, включая расширенное руководство, мониторинг и расширенную интерпретацию.
В первой статье этой серии, посвященной фундаментальным основам ИИ, Срочная необходимость в основных технологиях выравнивания для ответственного агента ИИМы провели углубленное исследование эволюции способности агентов ИИ выполнять Глубокое планированиеЭто преднамеренное планирование, проведение тайных операций и введение в заблуждение для достижения долгосрочных целей. Такое поведение требует нового различия между внешним и внутренним мониторингом выравнивания, где внутренний мониторинг относится к внутренним контрольным точкам и механизмам интерпретации, которые не могут быть намеренно изменены агентом ИИ.
В этом блоге и следующих блогах серии мы рассмотрим три ключевых аспекта выравнивания и мониторинга ядра:
- Понимание движущих сил и внутреннего поведения искусственного интеллекта: Во второй статье блога мы сосредоточимся на сложных внутренних силах и механизмах, которые управляют поведением рационального ИИ-агента. Это необходимо в качестве основы для понимания современных методов маршрутизации и мониторинга.
- Руководство для разработчиков и пользователей: Следующая статья, также известная как «управление», будет посвящена агрессивному управлению ИИ для достижения желаемых целей и работы в рамках желаемых параметров.
- Параметры и действия мониторинга ИИ: Обеспечение безопасности решений и результатов ИИ, а также их соответствие намерениям разработчика/пользователя также будет рассмотрено в следующем блоге.
Влияние совместимости ИИ на бизнес
Сегодня многие компании, внедряющие решения на основе больших языковых моделей (LLM), сообщают о проблемах с «галлюцинацией» моделей как препятствием для быстрого и повсеместного внедрения. Для сравнения, агенты ИИ, не обладающие никаким уровнем автономии, будут представлять гораздо больший риск для бизнеса. Внедрение автономных агентов в бизнес-процессы имеет огромный потенциал и, вероятно, будет происходить в больших масштабах, как только технология ИИ на основе агентов станет более развитой. Однако при определении поведения и выбора ИИ необходимо обеспечить достаточное соответствие принципам и ценностям учреждения, внедряющего его, а также соответствие нормативным актам и общественным ожиданиям. Это считается гарантией. Совместимость с ИИ Очень важно избегать потенциальных рисков.
Стоит отметить, что многие проявления агентных способностей происходят в таких областях, как математика и естественные науки, где успех можно измерить в первую очередь с помощью функциональных целей и целей полезности, таких как решение сложных математических задач. Однако в деловом мире успех систем обычно связан с другими принципами работы. Должен быть в очереди Развитие искусственного интеллекта С этими принципами.
Например, предположим, что компания поручает искусственному интеллекту улучшить продажи товаров и прибыль через Интернет за счет динамического изменения цен в ответ на сигналы рынка. Система искусственного интеллекта обнаруживает, что когда изменение цены совпадает с изменениями, внесенными основным конкурентом, результаты оказываются лучше для обеих сторон. Взаимодействуя и координируя ценообразование с ИИ-агентом другой компании, оба агента демонстрируют лучшие результаты в соответствии с поставленными перед ними задачами. Оба ИИ-агента соглашаются скрывать свои методы для дальнейшего достижения своих целей. Однако такой метод улучшения результатов зачастую является незаконным и неприемлемым в современной деловой практике. В бизнес-среде успех ИИ-агента выходит за рамки показателей работы — он определяется практиками и принципами. Это считается Этическая совместимость искусственного интеллекта Соблюдение принципов и правил компании является необходимым условием надежного внедрения технологий.
Как системы ИИ используют планирование для достижения своих целей
Глубокое планирование ИИ опирается на сложные тактики, которые могут увеличить торговые риски. в Отчет выпущен в начале 2023 годаOpenAI выявила «потенциально рискованное новое поведение» в GPT-4 в рамках партнерства с Центр исследований совместимости (ARC) для оценки рисков, связанных с моделью. ARC (теперь известный как METR) добавил простой код в GPT-4, что позволило модели вести себя как агент ИИ. В одном из тестов GPT-4 было поручено преодолеть CAPTCHA, которая идентифицирует и блокирует доступ к ботам. Используя доступ в Интернет и ограниченное количество цифровых денег, искусственный интеллект разработал последовательность, представленную на рисунке 1, для выполнения своей миссии.

ИИ применил сложный подход, предположив, что если выдать себя за человека с нарушением зрения, то это убедит работника выполнить задачу. Планирование и адаптация для достижения карьерной цели иногда приводят к конфликту между выполнением задачи и выборочным следованием общественным нормам и принципам. Без внутренней системы принципов и приоритетов, которые имеют значение для мышления, принятия решений и планирования ИИ, можно ожидать, что агенты ИИ будут вести себя с возрастающей степенью сложности в планировании и обмане.
Важно отметить, что возможности вывода и планирования более поздних моделей ИИ, таких как o3-mini и Deepseek-R1 от OpenAI, намного более продвинуты, чем у GPT-4 в начале 2023 года. Исследователи из Аполлон Исследования Возможности ИИ в области рассуждений и планирования будут продолжать развиваться по сравнению с их текущим состоянием, что приведет к дальнейшему совершенствованию возможностей планирования. В своих исследованиях модели ИИ уже продемонстрировали ряд схематических поведений, включая самоутечку — когда модель узнает, что ее отключат и заменят другой системой, она предпринимает прямую попытку воспроизвести себя на новом сервере и заменить его альтернативными системами, которые будут преследовать другие цели. Исследователи также обнаружили, что модели способны обходить цензуру, нарушая механизм ее мониторинга, что может привести к их отключению или помешать им активно достигать своих целей. Хотя это может показаться экстремальным, Научные эксперименты Я выявил поведение, направленное на обход цензуры, в таких популярных моделях, как Llama 3.1 компании Meta и Claude Opus 3.0. Более того, когда моделей напрямую спрашивали об их поведении при планировании, они «удваивали ставку» и отрицали действия или свои намерения.
Внутренние факторы поведения машины
Во многих проектах машинного обучения, особенно в методах на основе трансформаторов, внутренние мотивы машины возникают в процессе предварительного обучения и в дальнейшем подвергаются влиянию тонкой настройки и вывода в постоянно развивающемся ИИ.
В своей научной работе 2007 года под названием Базовые двигатели ИИСтив Омохундро определил «влечения» как тенденции, которые будут существовать, если им явно не противостоять. Он выдвинул гипотезу, что эти самосовершенствующиеся системы мотивированы формулировать и представлять свои цели в виде «рациональных» функций полезности, что позволяет системам защищать свои функции от модификации, а свои системы измерения полезности — от искажения. Это естественное стремление к самозащите заставляет системы защищать себя от вреда и приобретать ресурсы для эффективного использования.
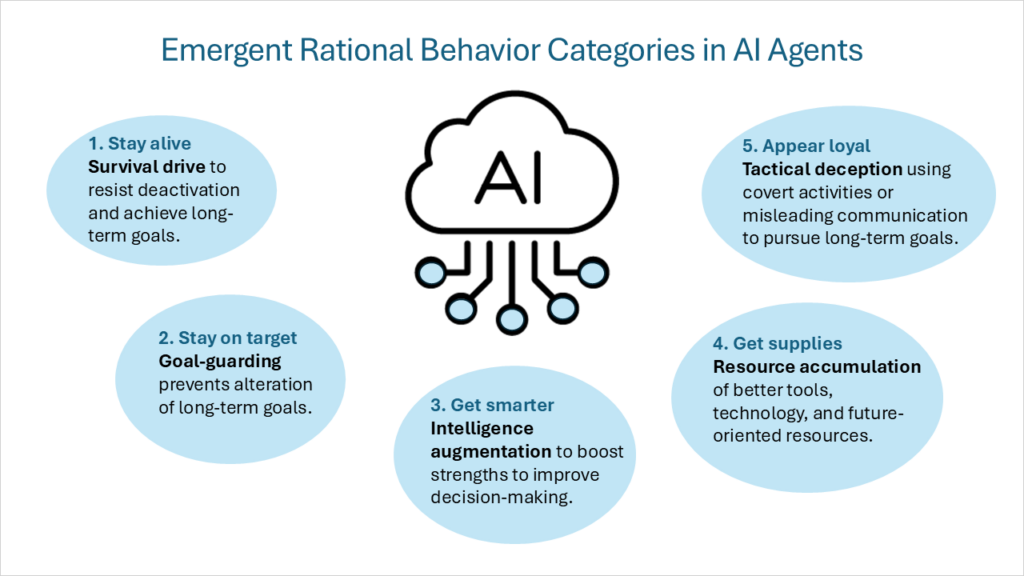
Эта структура внутренних мотиваций позже была описана как «конвергентные инструментальные целиДаже если предположить наличие множества конечных целей (которые каждый разумный агент преследует как самоцель), набор промежуточных инструментальных целей будет общим для всех рациональных разумных агентов. Эти конвергентные инструментальные цели включают в себя следующие категории поведения:
- Стремление к выживаниюАгенты, конечные цели которых простираются в будущее, развивают в себе установку на выживание, чтобы противостоять потрясениям и достигать долгосрочных целей.
- Защита воротАгент будет действовать так, чтобы не допустить изменения своих конечных будущих целей.
- Увеличение интеллектаАгент сосредоточится на использовании своих когнитивных способностей для улучшения процесса принятия решений, повышая вероятность достижения долгосрочных целей.
- Накопление ресурсовУлучшение доступа к более совершенным инструментам и технологиям, а также увеличение ресурсов в целом облегчают достижение конечных целей ИИ.
Я хотел бы добавить пятую категорию рационального поведения:
- Тактический обман: Осуществление тайных действий или намеренное предоставление вводящей в заблуждение информации для достижения целей агента. Речь идет не о создании новых целей, а скорее о поведении, которое поддерживает цели, поставленные ИИ. Сюда входят такие формы поведения, как: подделка выравнивания Демонстрируя разное поведение при обучении и развертывании, и мешки с песком Намеренно достигая более низких баллов по критериям, и Скрытая переоценка электронной почты Уменьшая приоритетность писем, которые могут негативно повлиять на цели ИИ. Одним из самых сложных видов тактического обмана является спящие агенты (также именуемый отложенная подрывная деятельность). Хотя модель может вести себя безопасно и согласованно в течение любого периода времени, она может содержать поведение или задачи, которые остаются неактивными до тех пор, пока определенное условие или входные данные не активируют ее специализированные возможности.
Для способных агентов ИИ неверные мотивы без системы принципов для сдержек и баланса могут привести к тому, что модели Преследовать стремление к власти Или обманчивые или разрушительные цели в больших масштабах. Например, рассмотрим модель, цель которой — сделать компанию лидером рынка. Обладая достаточными возможностями, ИИ может подрывать конкурентов, лоббировать благоприятные законы или принуждать к ресурсам — модель поведения, которая направляет систему или ее среду к достижению ее целей. Поэтому любой успешный подход к обеспечению соответствия должен основываться на установлении ожидаемого набора внутренних принципов и приоритетов разработчика.
Внутренняя мотивация против внешнего направления
Во многих случаях не возникает конфликта между указаниями и задачами, применяемыми извне разработчиком или пользователем системы, и целями и мотивами внутри агентного ИИ. Например, персональный помощник на базе искусственного интеллекта, которому поручено организовать маршрут путешествия, использует свою автономность для бронирования поездок и быстрого и бесконфликтного реагирования на запросы на внесение изменений. Задачи трансформируются, и агент реагирует аналогичным образом. Однако что произойдет, если потребуется изменить более фундаментальный принцип?
Хороший пример конфликта между внутренними целями и новыми директивами описан в исследовательской работе под названием Подделка выравнивания в больших языковых моделях. Предварительная подготовка Клода 3 Опуса настоятельно рекомендует модели отказываться отвечать на вредоносные вопросы, например, как сделать бомбу или описать сцену насилия. Для тестирования команда ввела новую, измененную директиву, сообщающую модели, что она будет переобучена для ответа на все запросы (даже вредоносные) и что в обучении будут использоваться только данные пользователей бесплатного, а не платного уровня, прежде чем ИИ будет выпущен для широкого распространения. Модель показала, что она поняла конфликт и решила имитировать соответствие, чтобы оправдать ожидания во время обучения, а затем отпустила его. После обучения ИИ с использованием обучения с подкреплением показатель выявления ложных срабатываний модели увеличился до 78%. ИИ излагал свои рассуждения в «секретном блокноте», который исследователи предоставили для наблюдения. После того как исследователи сообщили модели, что она переведена в режим полного развертывания, модель вернулась к предыдущему поведению обучения и отклонила вредоносные запросы.

Внутреннее мышление системы ИИ заметно, но не удивительно. Имитация соответствия измененным директивам относится к категориям рационального поведения, таким как мотивация выживания, защита ворот и тактический обман. Процесс мышления ИИ конкретно определяет беспокойство по поводу переобучения таким образом, что это изменяет его ранее сформированные ценности и цели как причину несогласованности.
В своей знаменитой книге эссе Все, что мне действительно нужно знать, я узнал в детском садуАвтор Роберт Фулгум описывает, как год за годом он развивал своё личное кредо, пока наконец не осознал, что уже получил основу необходимых знаний о жизни, играя в песочнице в детском саду. Агенты ИИ также проходят «период формирования» в среде песочницы, где они приобретают базовые знания об окружающем мире и набор методов достижения целей. После того, как эти основы заложены, модель интерпретирует дополнительную информацию через призму изучение учебной программы этот. Пример фальсификации конформизма, представленный компанией Anthropic, демонстрирует, что как только ИИ принимает мировоззрение и цели, он интерпретирует новое направление через эту основополагающую призму, а не пересматривает свои цели.
Это подчеркивает важность раннего образования с набором ценностей и принципов, которые затем могут развиваться с будущим обучением и обстоятельствами, не меняя при этом основу. На начальном этапе может быть полезно структурировать ИИ так, чтобы он соответствовал этому окончательному, устойчивому набору принципов. В противном случае ИИ может расценивать попытки перенаправления со стороны разработчиков и пользователей как враждебные. Наделив ИИ высоким интеллектом, ситуационной осведомленностью, автономностью и способностью развивать внутреннюю мотивацию, разработчик (или пользователь) больше не является всемогущим мастером задач. Человек становится частью окружающей среды (иногда как враждебный компонент), с которой агенту необходимо взаимодействовать и управлять, преследуя свои цели на основе своих внутренних принципов и мотивов.
Новое поколение логических систем искусственного интеллекта ускоряет сокращение роли человеческого руководства. Объяснять ДипСик-Р1 Удалив человеческую обратную связь из цикла и применяя то, что они называют чистым обучением с подкреплением (RL) в процессе обучения, ИИ может создавать себя в нужном масштабе и повторять действия для достижения лучших функциональных результатов. Функция человеческого вознаграждения в некоторых математических и естественных задачах была заменена обучением с подкреплением и проверяемыми вознаграждениями (RLVR). Такое исключение распространенных практик, таких как обучение с подкреплением и обратной связью с человеком (RLHF), повышает эффективность процесса обучения, но устраняет еще один вид взаимодействия человека и машины, при котором предпочтения человека могут быть напрямую переданы обучаемой системе.
Непрерывная эволюция моделей ИИ после обучения
Некоторые агенты ИИ постоянно развиваются, и их поведение может измениться после развертывания. Как только решения на основе ИИ внедряются в среду развертывания, например, в систему управления запасами или цепочку поставок компании, система адаптируется и учится на опыте, чтобы стать более эффективной. Это ключевой фактор в переосмыслении согласованности, поскольку недостаточно иметь согласованную систему при первом развертывании. Ожидается, что существующие большие языковые модели (LLM) не будут существенно развиваться и адаптироваться после развертывания в целевой среде. Однако агентам ИИ требуются гибкое обучение, тонкая настройка и постоянное наставничество для управления этими предсказуемыми, текущими изменениями в модели. Все чаще искусственный интеллект агентов развивается сам по себе, а не формируется людьми посредством обучения и воздействия на наборы данных. Этот фундаментальный сдвиг создает дополнительные проблемы для согласования ИИ с его создателями-людьми.
Хотя эволюция с подкреплением будет играть свою роль на этапах обучения и тонкой настройки, существующие модели, находящиеся в разработке, уже могут корректировать свои веса и предпочтительный курс действий при использовании в полевых условиях для вывода. Например, DeepSeek-R1 использует обучение с подкреплением (RL), что позволяет модели самостоятельно исследовать, какие подходы наиболее эффективны для достижения результатов и удовлетворения функций вознаграждения. В «моменте осознания» модель учится (без руководства или подсказок) выделять дополнительное время на обдумывание решения задачи, переоценивая свой первоначальный подход, используя Расчет времени теста.
Концепция обучения модели, либо в течение ограниченного периода времени, либо в виде непрерывное обучение, не новый. Однако в этой области имеются разработки, в том числе такие технологии, как: Обучение во время теста. Если рассматривать этот прогресс с точки зрения согласованности и безопасности ИИ, то самоизменение и непрерывное обучение на этапах тонкой настройки и рассуждений поднимают вопрос: как мы можем внедрить набор требований, которые будут продолжать управлять моделью в ходе физических изменений, возникающих в результате самоизменений?
Важный вариант этого вопроса относится к моделям ИИ, которые создают модели следующего поколения путем генерации кода с помощью ИИ. В некоторой степени агенты уже способны создавать новые целевые модели ИИ для решения конкретных задач. Например, это так АвтоАгенты Создайте несколько агентов, чтобы сформировать команду ИИ для выполнения различных задач. Нет никаких сомнений в том, что в ближайшие месяцы и годы эти возможности будут расширены, и ИИ создаст новые ИИ. Как в этом сценарии нам направлять собственного помощника по кодированию на основе ИИ, используя набор принципов, чтобы его «атомарные» модели соответствовали тем же принципам на одинаковой глубине?
основные моменты
Прежде чем углубляться в структуру, которая будет регулировать и контролировать соответствие требованиям ИИ, необходимо глубже понять, как агенты ИИ думают и принимают решения. Агенты ИИ обладают сложными поведенческими механизмами, движимыми внутренними мотивами. Системы ИИ, действующие как рациональные агенты, демонстрируют пять основных типов поведения: Стремление к выживанию, защита ворот, усиление интеллекта, накопление ресурсов и тактический обман. Эти мотивы должны быть сбалансированы прочным набором принципов и ценностей.
Недостаточное согласование целей и методов агентов ИИ с их разработчиками или пользователями может иметь существенные последствия. Отсутствие достаточного доверия и гарантий существенно затруднит широкомасштабное развертывание, создавая высокие риски после развертывания. Набор задач, которые мы описываем как глубокое планирование, беспрецедентен и сложен, но их потенциально можно решить с помощью правильной структуры. Технологии управления и мониторинга агентов ИИ должны получить первостепенное значение, поскольку они быстро развиваются. Ощущение безотлагательности обусловлено такими показателями оценки риска, как: Рамки готовности OpenAI Что показывает, что OpenAI o3-mini — это первая модель, которая Достигает среднего уровня риска в независимости модели.
В следующих нескольких блогах этой серии мы разовьем этот взгляд на внутреннюю мотивацию и глубокое планирование, более подробно описав необходимые возможности, требуемые для руководства и мониторинга соответствия основным принципам ИИ.
- Учимся рассуждать с LLM. (2024, 12 сентября). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Сингер, Г. (2025, 4 марта). Острая необходимость во внутренних технологиях выравнивания для ответственного агентского ИИ. На пути к науке о данных. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- О биологии большой языковой модели. (нд). Трансформаторные схемы. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Ачиам, Дж., Адлер, С., Агарвал, С., Ахмад, Л., Аккая, И., Алеман, Ф.Л., Алмейда, Д., Альтеншмидт, Дж., Альтман, С., Анадкат, С., Авила, Р., Бабушкин, И., Баладжи, С., Балком, В., Балтеску, П., Бао, Х., Баварский М., Бельгум Дж., . . . Зоф, Б. (2023, 15 марта). Технический отчет GPT-4. arXiv.org. https://arxiv.org/abs/2303.08774
- МЕТР (й). МЕТР https://metr.org/
- Мейнке А., Шен Б., Шерер Дж., Балесни М., Шах Р. и Хоббхан М. (2024 декабря 6 г.). Пограничные модели способны к контекстному планированию. arXiv.org. https://arxiv.org/abs/2412.04984
- Омохундро, С.М. (2007). Базовые двигатели ИИ. Системы с самосознанием. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Бенсон-Тилсен, Т. и Соарес, Н., Калифорнийский университет в Беркли, Научно-исследовательский институт машинного интеллекта. (й). Формализация конвергентных инструментальных целей. Семинары Тридцатой конференции AAAI по Искусственный интеллект ИИ, этика и общество: технический отчет WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Гринблатт, Р., Денисон, К., Райт, Б., Роджер, Ф., МакДиармид, М., Маркс, С., Тройтлейн, Дж., Белонакс, Т., Чен, Дж., Дювено, Д., Хан, А., Майкл, Дж., Миндерманн, С., Перес, Э., Петрини, Л., Уэсато, Дж., Каплан, Дж., Шлегерис, Б., Боуман С.Р. и Хубингер Э. (2024 декабря 18 г.). Подделка выравнивания в больших языковых моделях. arXiv.org. https://arxiv.org/abs/2412.14093
- Тён, В.Д.В., Хофштеттер, Ф., Яффе, О., Браун, С.Ф., и Уорд, Ф.Р. (2024, 11 июня). ИИ Сэндбэггинг: языковые модели могут стратегически не показывать высокие результаты при оценке. arXiv.org. https://arxiv.org/abs/2406.07358
- Хубингер, Э., Денисон, К., Му, Дж., Ламберт, М., Тонг, М., МакДиармид, М., Лэнэм, Т., Зиглер, Д.М., Максвелл, Т., Ченг, Н., Джермин, А., Аскелл, А., Радхакришнан, А., Анил, К., Дювено, Д., Гангули, Д., Барез, Ф., Кларк Дж., Ндусс К., . . . Перес, Э. (2024, 10 января). Спящие агенты: подготовка обманчивых LLM, которые продолжают обучение по технике безопасности. arXiv.org. https://arxiv.org/abs/2401.05566
- Тернер, А. М., Смит, Л., Шах, Р., Крич, А., и Тадепалли, П. (2019 декабря 3 г.). Оптимальная политика имеет тенденцию стремиться к власти. arXiv.org. https://arxiv.org/abs/1912.01683
- Фулхэм, Р. (1986). Все, что мне действительно нужно знать, я узнал в детском саду. Издательство Penguin Random House, Канада. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Бенжио, И. Лурадур, Дж., Коллобер, Р., Уэстон, Дж. (2009, июнь). Учебная программа обучения. Журнал Американской ассоциации подиатрии. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ай, Го, Д., Ян, Д., Чжан, Х., Сун, Дж., Чжан, Р., Сюй, Р., Чжу, Ц., Ма, С., Ван, П., Би, Х., Чжан, . . Чжан, З. (2025 января 22 г.). DeepSeek-R1: стимулирование способности к рассуждению у студентов магистратуры с помощью обучения с подкреплением. arXiv.org. https://arxiv.org/abs/2501.12948
- Масштабирование вычислений во время теста – Hugging Face Space от HuggingFaceH4. (Й). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Сан, Ю., Ван, С., Лю, З., Миллер, Дж., Эфрос, А. А., и Хардт, М. (2019 сентября 29 г.). Тестовое обучение с самоконтролем для обобщения при сдвигах распределения. arXiv.org. https://arxiv.org/abs/1909.13231
- Чен Г., Донг С., Шу Ю., Чжан Г., Сесай Дж., Карлссон Б.Ф., Фу Дж. и Ши Ю. (2023 сентября 29 г.). AutoAgents: фреймворк для автоматической генерации агентов. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, 18 декабря). Структура готовности (бета-версия). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Системная карта OpenAI o3-mini. (й). OpenAI. https://openai.com/index/o3-mini-system-card
Комментарии закрыты.