

Рейтинг аудитории: 27 моделей ИИ, ChatGPT на 8-м месте — вот модели, которые его превзошли
Хотя мир Искусственный интеллект (ИИ) Хотя зачастую это может показаться неспокойной сферой, за кулисами происходит удивительно большой объем анализа, сравнительного анализа и тестирования — причем не только самими компаниями, но и группами, созданными для определения собственных рейтингов.

Эти группы проверяют всё: от способности чат-бота выполнять математические тесты,
Даша, или дать логические объяснения, или даже дать медицинский совет, или просто показать, насколько она эмоциональна.
В ходе этих разнообразных испытаний модели демонстрируют свои сильные и слабые стороны в разных областях. Например, GPT-5 Он преуспел в научной дедукции, но отстает от таких людей, как Джемини и Клод, в способности адаптироваться к новым концепциям.
Каждый из этих тестов даёт нам что-то новое о моделях ИИ и важен для понимания того, какие инструменты лучше всего подходят для разных сценариев. Но часто упускается один важный показатель: какие модели ИИ обеспечивают наилучший пользовательский опыт?
Система классификации человека
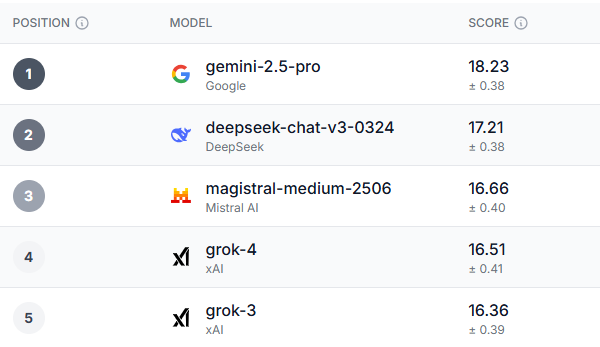
Британская технологическая компания Prolific создала Таблица лидеров ИИ под названием HumaineВместо того чтобы тестировать способность ИИ выполнять задачи, Prolific протестировала различный пользовательский опыт с этими моделями.
Оценив опыт 21 352 человек с помощью инструментов, они не только смогли выявить общего победителя, но и разбить результаты по возрасту, местоположению (тестирование проводилось как в Великобритании, так и в США) и политическим убеждениям.
Сюда входят отдельные листинги для:
- Великобритания: Возрастные группы
- Соединенное Королевство: Раса
- Соединенное Королевство: политическая точка зрения
- Соединенные Штаты: Возрастные группы
- Соединенные Штаты: Раса
- Соединенные Штаты: политическая точка зрения
Команда попросила каждого участника взаимодействовать с двумя отдельными моделями ИИ для сравнения и попросила их предоставить обратную связь о том, какая модель показала лучшие результаты в каждом взаимодействии.
В результате был выявлен общий победитель и составлена таблица лидеров по производительности, а также отдельные рейтинги по основным показателям выполнения задач и логическому мышлению, а также победитель по показателям коммуникабельности, устойчивости, доверия и этики.
Что показывают результаты?

После тщательного анализа был выявлен явный победитель не только в категории общей производительности, но и в большинстве подкатегорий. Gemini 2.5-Pro превзошёл все ожидания практически во всех рассмотренных тестах.
Молодые люди в возрасте 18-34 лет в Великобритании, избиратели-демократы и люди старше 55 лет в США согласились с тем, что Близнецы 2.5 Про Это лучшая модель в целом. Единственной областью, где все демографические показатели оказались выше, чем у Gemini, были доверие, этика и безопасность, и это был Grok-3 — несколько ироничный вывод, учитывая некоторые проблемы безопасности и этики, с которыми недавно столкнулись модели ИИ.
Интересно, что три модели, появившиеся после Gemini, — это Deepseek, Magistral Le Chat и GrokХотя Deepseek пользовался большой популярностью в начале этого года, в последнее время он исчез из поля зрения. Le Chat, напротив, менее популярен, но у него есть преданные поклонники.
Так какое же место во всём этом занимает всемирно известный ChatGPT? Он находится в самом низу списка, на восьмом месте, с моделью GPT-4.1 с самым высоким рейтингом. Ещё хуже то, Клод, где четыре выпуска заняли одиннадцатое и двенадцатое места в общем зачете.
Так что же все это значит?
Означает ли это, что Gemini — лучший чат-бот с искусственным интеллектом в мире? Означает ли это, что вам стоит отказаться от ChatGPT…? Ну, не совсем.
Эти результаты не обязательно отражают эффективность этих моделей. При тестировании по большинству других показателей на первых позициях обычно оказываются ChatGPT, Gemini, Claude и Grok.
Тем не менее, это важное дополнение к этим тестам. Они помогают нам лучше понять ИИ с точки зрения человеческого опыта. Например, Le Chat не показывает высоких результатов по стандартным тестам, но его часто называют отличным выбором с точки зрения опыта и надёжности.
Хотя производительность Anthropic и OpenAI в этом раунде тестов не достигла такого уровня, Gemini и Grok продемонстрировали ещё один сильный результат. Обе компании часто добиваются высоких результатов в стандартных бенчмарках, и здесь они продолжают это делать.
Комментарии закрыты.