

Достижение уверенности в больших языковых моделях (LLM) с использованием интеллектуальных схем принятия решений
Неопределенность не является чем-то новым в технологиях — все современные системы преодолевают неопределенность входных и выходных данных, используя математически обоснованные структуры управления.
Перспектива появления агентов на базе искусственного интеллекта покорила мир. Агенты могут взаимодействовать с окружающим миром, писать статьи (но не эту), выполнять действия от вашего имени и в целом делать сложную часть автоматизации любой задачи простой и доступной.
Агенты берутся за самые сложные участки операций и быстро решают проблемы. Иногда слишком быстро. Если ваш агентский процесс требует участия человека для принятия решения о результате, этап проверки человеком может стать узким местом в процессе.
Примером агентского процесса является обработка и классификация телефонных звонков клиентов. Даже агент с точностью 99.95% допустит 5 ошибок, прослушивая 10,000 XNUMX звонков. Несмотря на то, что агент знает это, он не может вам сказать. Который 5 из 10,000 XNUMX вызовов были классифицированы неправильно.

Метод «LLM-as-a-Judge» — это метод, при котором вы передаете каждый входной сигнал в другой процесс LLM, чтобы оценить, является ли выходной сигнал, полученный на основе входных данных, правильным. Однако, поскольку это еще один процесс получения степени магистра права, он также может быть неточным. Эти две вероятностные операции создают матрицу путаницы с истинно положительными, ложно отрицательными, истинно отрицательными и ложно положительными результатами.
Другими словами, запись, которая правильно классифицирована процессом LLM, может быть признана неверной ее судьей LLM, и наоборот.
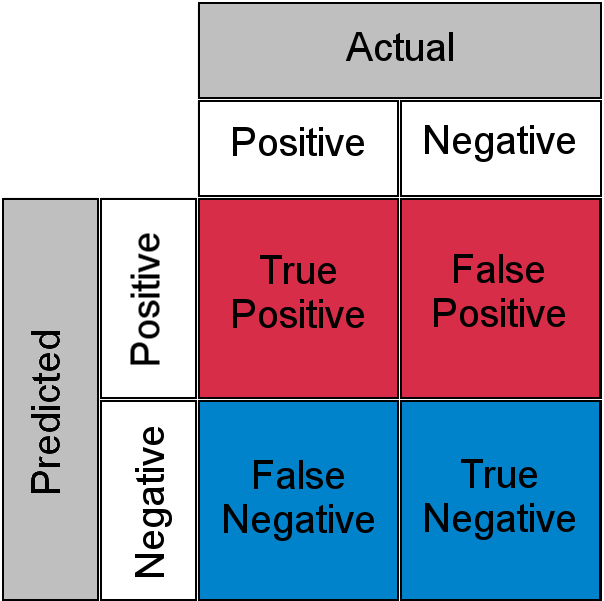
из-за этого " Неизвестное известное «Для чувствительной рабочей нагрузки человек должен просмотреть и понять все 10,000 XNUMX вызовов. Мы снова возвращаемся к той же проблеме узкого места.
Как повысить статистическую достоверность наших процессов, управляемых агентами? В этой статье я создаю систему, которая позволяет нам повысить достоверность наших процессов, управляемых агентами, обобщаю её на произвольное количество агентов и разрабатываю функцию стоимости, которая поможет определить будущие инвестиции в систему. Код, который я использую в этой статье, доступен в моём репозитории. схемы-решения-ИИ.
Схемы принятия решений ИИ
Обнаружение и исправление ошибок — не новые концепции. Исправление ошибок имеет решающее значение в таких областях, как цифровая и аналоговая электроника. Даже достижения в области квантовых вычислений зависят от расширения возможностей исправления и обнаружения ошибок. Мы можем черпать вдохновение из этих систем и реализовать нечто подобное с помощью агентов ИИ. Например, вы можете Алгоритмы искусственного интеллекта Расширенное использование методов исправления ошибок, применяемых в системах связи.
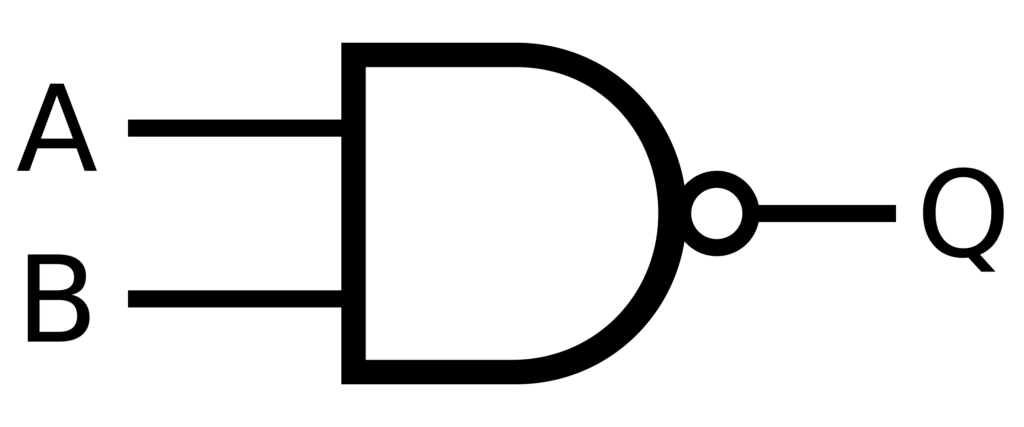
В булевой логике элементы NAND являются святым Граалем вычислений, поскольку они могут выполнять любую операцию. Он функционально завершен, то есть любая логическая операция может быть создана с использованием только вентилей NAND. Этот принцип можно применить к системам искусственного интеллекта для создания надежных структур принятия решений со встроенной коррекцией ошибок. Это позволяет создавать нейронные сети Более надежен и способен обрабатывать неполные или зашумленные данные.
От электронных схем до схем интеллектуального принятия решений (ИИ)
Так же, как электронные схемы используют повторение и проверку для обеспечения надежности вычислений, схемы интеллектуального принятия решений (ИИ) могут использовать несколько агентов с разными точками зрения для получения более точных результатов. Эти схемы можно построить, используя принципы теории информации и булевой логики:
- Избыточная обработка: Несколько агентов ИИ обрабатывают одни и те же входные данные независимо друг от друга, подобно тому, как современные процессоры используют избыточные схемы для обнаружения аппаратных ошибок. Этот процесс повышает надежность системы ИИ.
- Механизмы консенсуса: Результаты принятия решений объединяются с использованием систем голосования или средневзвешенных значений, аналогично мажоритарным логическим вентилям в отказоустойчивой электронике. Эти механизмы гарантируют, что окончательное решение отражает консенсус среди агентов.
- Агенты-валидаторы: Специализированные аудиторы ИИ проверяют обоснованность выходных данных, работая аналогично кодам обнаружения ошибок, таким как Биты четности Или циклические проверки избыточности (проверки CRC). Эти агенты снижают вероятность принятия неправильных решений.
- Интеграция с участием человека: Стратегическая человеческая проверка на ключевых этапах процесса принятия решений, аналогично тому, как биометрические системы используют человеческий контроль в качестве конечного уровня проверки. Это гарантирует, что важные решения будут оцениваться человеком.
Математические основы схем принятия решений в искусственном интеллекте
Надежность этих систем можно количественно определить с помощью теории вероятностей.
С одной стороны, вероятность отказа определяется точностью, наблюдаемой с течением времени в наборе тестовых данных, хранящемся в такой системе, как ЛэнгСмит.

Для 90%-ного фактора точности вероятность отказа, p_1، 1–0.9 Это 0.1 или 10%.

Вероятность того, что два независимых фактора не дадут результата при одних и тех же входных данных, равна вероятности того, что оба фактора окажутся точными, умноженной друг на друга:
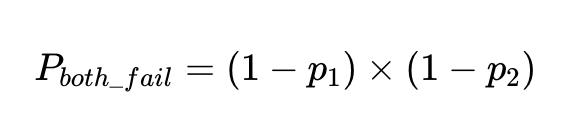
Если у нас есть N выполнений с этими клиентами, общее количество отказов равно
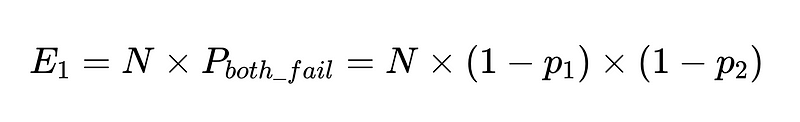
Таким образом, для 10,000 90 выполнений между двумя независимыми исполнителями с точностью 100% ожидаемое количество сбоев составит XNUMX.
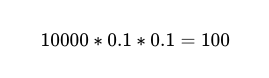
Однако мы до сих пор не знаем. Который Из этих 10,000 100 телефонных звонков XNUMX действительно заканчиваются неудачей.
Мы можем объединить четыре варианта этой идеи, чтобы получить более надежное решение, обеспечивающее уверенность в любом ответе:
- Базовый классификатор (простое разрешение выше)
- Резервное копирование (простое решение выше)
- Проверка схемы (например, разрешение 0.7)

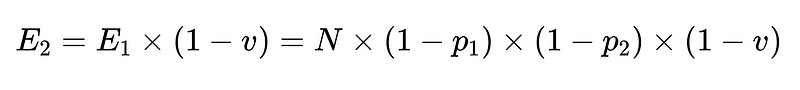
- Наконец, отрицательный валидатор (например, n = точность 0.6)
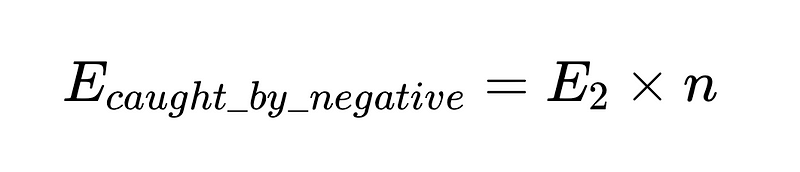
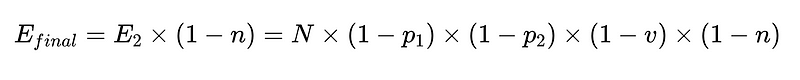
Чтобы закодировать это (Полный склад), мы можем использовать Питон базовый:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESОбъединив эти операции с логикой, Логический Проще говоря, мы можем получить одинаковую точность и уверенность в каждом ответе:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Логика принятия решений: пошаговое объяснение
Шаг 1: Когда система контроля качества дает сбой
if not validation_result:Это означает: «Если наш эксперт по контролю качества (аудитор) отклоняет первоначальный анализ, не доверяйте ему». Затем система пытается использовать резервное мнение. Если и это не проходит проверку, дело передается на рассмотрение специалисту-человеку. Эта процедура гарантирует, что вам не придется полагаться на неточные данные.
Проще говоря: «Если что-то не так с нашим первым ответом, давайте попробуем наш запасной метод. Если это все еще сомнительно, давайте попросим вмешаться эксперта-человека». Это гарантирует правильное рассмотрение сложных случаев.
Шаг 2: Устранение несоответствий
if negative_check == 'no' and primary_result['call_type'] is not None:На этом этапе проверяется наличие определенного типа несоответствия: «Наш отрицательный результат проверки указывает на то, что не должно быть типа колл, но наш фундаментальный аналитик все равно обнаружил тип пут».
В таких случаях система полагается на резервного аналитика для достижения безубыточности:
- Если резервный аналитик соглашается, что тип вызова отсутствует, он отправляется человеческому элементу.
- Если резервный аналитик согласен с основным аналитиком, то он принимается, но со средней уверенностью.
- Если у резервного аналитика другой тип вызова ← он отправляется человеческому элементу
Это все равно, что сказать: «Если один эксперт говорит: «Это не поддается классификации», а другой утверждает, что это так, нам нужен решающий судья или человек». Этот механизм необходим для обеспечения точной классификации типов вызовов и снижения возможных ошибок.
Шаг 3: Когда эксперты приходят к согласию
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Когда и основной, и резервный аналитики независимо друг от друга приходят к одному и тому же выводу, система отмечает его как «высокую достоверность» — это наилучший сценарий. Эта идеальная ситуация возникает, когда результаты множественных анализов полностью совпадают.
Проще говоря: «Если два разных эксперта, используя разные методы, независимо друг от друга приходят к одному и тому же выводу, мы можем быть совершенно уверены, что их вывод верен». Это отражает консенсус экспертов, что является весомым показателем точности и надежности.
Шаг 4: Обработка по умолчанию
Если ни одно из особых условий не применимо, система по умолчанию использует результат основного аналитика со «средней» степенью достоверности. Если основной аналитик не может определить тип звонка, он передает дело на рассмотрение специализированному аналитику-человеку.
Важность этого подхода в уменьшении количества ошибок
Эта логика способствует построению сильной системы путем:
- Уменьшение ложных срабатыванийСистема обеспечивает высокую достоверность только в случае совпадения результатов нескольких методов, что значительно снижает количество ложных срабатываний.
- Обнаружение противоречийЕсли разные части системы различаются, это либо снижает доверие, либо передает вопрос на рассмотрение проверяющим, гарантируя, что ни одна потенциальная проблема не будет упущена.
- Умная эскалацияРецензенты рассматривают только те дела, которые действительно требуют их экспертных знаний, что повышает эффективность процесса рассмотрения и снижает нагрузку на человеческие ресурсы.
- Назначение трастаРезультаты включают уровень достоверности системы, что позволяет последующим процессам по-разному обрабатывать результаты с высокой и средней достоверностью, что имеет решающее значение для принятия обоснованных решений.
Этот подход аналогичен тому, как электроника использует избыточные схемы и механизмы голосования для предотвращения сбоев системы из-за ошибок. В системах искусственного интеллекта такая продуманная логика интеграции может значительно снизить количество ошибок, эффективно используя рецензентов-людей только там, где они приносят наибольшую пользу. Это обеспечивает оптимизацию ресурсов и одновременное сокращение количества ошибок, что приводит к созданию более надежной и точной системы.
пример
В 2015 году Департамент водоснабжения города Филадельфия опубликовал Статистика обращений клиентов по категориям. Понимание звонков клиентов — очень распространенный процесс, с которым сталкиваются агенты. Вместо того чтобы заставлять человека прослушивать каждый телефонный звонок клиента, агент может гораздо быстрее прослушать звонок, извлечь информацию и классифицировать звонок для дальнейшего анализа данных. Для управления водными ресурсами это важно, поскольку чем раньше будут выявлены критические проблемы, тем быстрее их можно будет решить.
Мы можем создать опыт. Я использовал большую языковую модель (LLM) для создания поддельных стенограмм телефонных звонков, о которых идет речь, задав вопрос: «Для данного класса создайте короткую версию этого телефонного звонка: Вот некоторые из этих примеров с доступом к полному файлу. здесь:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Теперь мы можем провести эксперимент с более традиционной оценкой, используя большую языковую модель в качестве судьи (Полная реализация здесь):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeПередавая в большую языковую модель (LLM) только текст, мы можем выделить истинные знания класса из извлеченного класса, который возвращается, и сравнить.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultВыполнение этого теста на всем синтетическом наборе данных с использованием Claude 3.7 Sonnet (последняя модель на момент написания статьи) показало очень высокую производительность: 91% вызовов были классифицированы правильно:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Если бы это были реальные звонки и у нас не было бы предварительных сведений о категории, нам все равно пришлось бы просмотреть все 100 телефонных звонков, чтобы найти 9 неправильно классифицированных звонков.
Применяя нашу мощную схему принятия решений, описанную выше, мы получаем аналогичные результаты точности, а также уверенность В этих ответах. В этом случае общая точность составляет 87%, а точность наших высокоуверенных ответов — 92.5%.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Нам нужна 100% точность в наших высоконадежных ответах, поэтому нам еще многое предстоит сделать. Такой подход позволяет нам углубиться в причина Неточность ответов с высокой степенью уверенности. В этом случае слабые утверждения и простые возможности проверки не охватывают все проблемы, что приводит к ошибкам классификации. Эти возможности можно многократно улучшать для достижения 100% точности высоконадежных ответов.
Улучшения системы фильтрации для повышения достоверности результатов.
Действующая система классифицирует ответы как «высокую степень достоверности», если мнения основного и резервного аналитиков совпадают. Чтобы достичь более высокой точности, мы должны быть более избирательны в отношении того, что считается «высокой достоверностью».
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Добавляя дополнительные критерии квалификации, мы получим меньше результатов с «высокой степенью достоверности», но они будут более точными. Это улучшение системы фильтрации направлено на сокращение количества ошибок и повышение надежности данных, классифицируемых как высококачественные.
Дополнительные методы проверки: повышение точности анализа
Вот еще несколько идей по улучшению процесса проверки и анализа данных:
Третичный анализаторДобавьте третий независимый метод анализа. Этот метод служит дополнительным уровнем проверки, сравнивая результаты двух различных аналитических методов с результатом третьего метода, чтобы обеспечить большую точность и снизить вероятность ошибок.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Сопоставление исторических образцов:Сравните результаты с исторически правильными результатами (например, векторный поиск). Этот метод использует надежные исторические данные в качестве эталона и сравнивает с ними текущие результаты для выявления любых отклонений или несоответствий. Его можно считать своего рода «памятью» для анализа, помогающей обнаруживать аномалии или неожиданные ситуации.
if similarity_to_known_correct_cases(primary_result) > 0.95:Состязательное тестированиеПримените небольшие изменения к входным данным и проверьте, остается ли классификация стабильной. Целью этого метода является проверка надежности и устойчивости системы классификации путем внесения в нее незначительных изменений в данные. Если система очень чувствительна к этим изменениям, это может указывать на потенциальные слабости или предубеждения.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Общая формула для вмешательства человека в систему извлечения LLM
- N = Общее количество казней (в нашем примере 10,000 XNUMX)
- p_1 = точность базового анализатора (0.8 в нашем примере)
- p_2 = точность резервного синтаксического анализатора (0.8 в нашем примере)
- v = эффективность валидатора схемы (0.7 в нашем примере)
- n = эффективность отрицательной проверки (0.6 в нашем примере)
- H = количество требуемых вмешательств человека
- E_final = окончательные необнаруженные ошибки
- m = количество независимых аудиторов
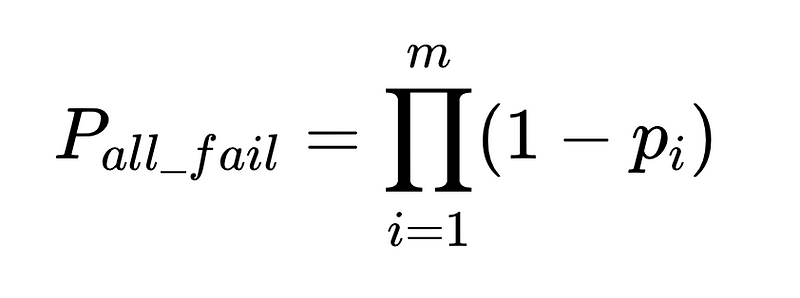
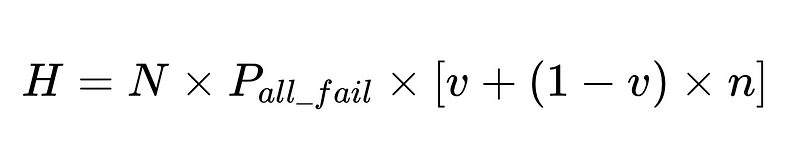
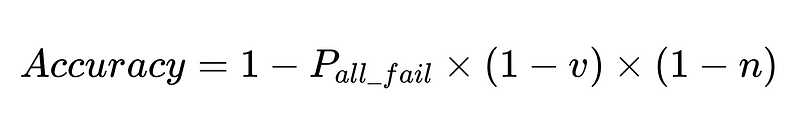
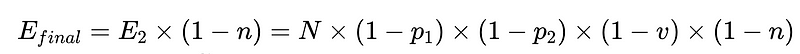
Оптимальная конструкция системы
Уравнение раскрывает ключевые аспекты точности системы обработки естественного языка (NLP):
- Добавление парсеров снижает накладные расходы, но повышает общую точность.
- Точность системы ограничена:
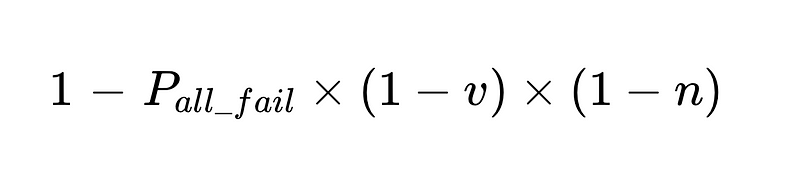
- Человеческое вмешательство пропорционально Напрямую Всего казнено N человек.
Например:
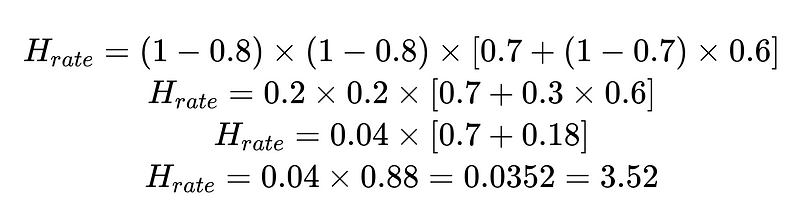
Мы можем использовать рассчитанный показатель человеческого вмешательства (H_rate) для отслеживания эффективности нашего решения в режиме реального времени. Если уровень человеческого вмешательства начинает превышать 3.5%, мы понимаем, что система дает сбой. Если уровень человеческого вмешательства постоянно снижается до менее 3.5%, мы знаем, что наши оптимизации работают так, как и ожидалось.
функция стоимости
Мы также можем создать функцию затрат, которая поможет нам улучшить нашу систему. Функция затрат — мощный аналитический инструмент для оценки финансовых показателей системы и выявления потенциальных областей для улучшения.
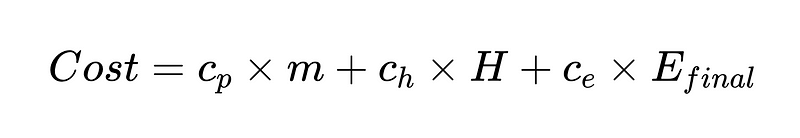
Имя:
- c_p = стоимость работы одного парсера (в нашем примере 0.10 долл. США)
- m = количество запусков синтаксического анализатора (в нашем примере 2 * N)
- H = Количество случаев, требующих вмешательства человека (352 из нашего примера)
- c_h = стоимость одного человеческого вмешательства (например, 200 долл.: 4 часа по 50 долл./час)
- c_e = стоимость одной необнаруженной ошибки (например, 1000 долларов США)
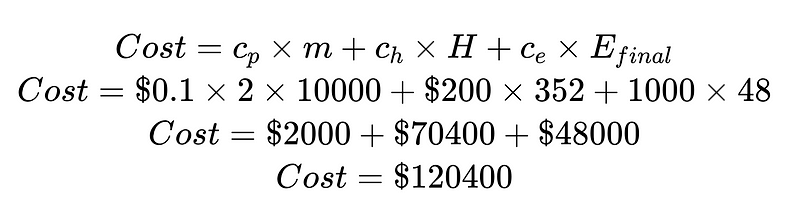
Разделив стоимость на стоимость человеческого вмешательства и стоимость необнаруженных ошибок, мы можем улучшить систему в целом. В этом примере, если стоимость человеческого вмешательства (70,400 48,000 долларов США) нежелательна и требует больших затрат, мы можем сосредоточиться на повышении достоверности результатов. Если стоимость необнаруженных ошибок (XNUMX XNUMX долларов США) нежелательна и требует больших затрат, мы можем внедрить синтаксические анализаторы Plus для снижения доли необнаруженных ошибок.
Конечно, функции затрат наиболее полезны как способы исследования того, как улучшить ситуации, которые они описывают.
Из вышеприведенного сценария, чтобы уменьшить количество необнаруженных ошибок, E_final, на 50%, где
- р1 и р2 = 0.8,
- v = 0.7 и
- N = 0.6
У нас есть три варианта:
- Добавление нового анализатора грамматики с точностью 50% и его включение в качестве вторичного анализатора. Обратите внимание, что это влечет за собой определенные компромиссы: стоимость работы анализаторов грамматики Plus увеличивается вместе с ростом стоимости человеческого вмешательства.
- Улучшить существующие грамматические анализаторы на 10% каждый. Это может быть возможно или невозможно из-за сложности задачи, выполняемой этими синтаксическими анализаторами.
- Улучшить процесс аудита на 15%. Опять же, это увеличивает стоимость за счет человеческого вмешательства.
Будущее доверия к ИИ: построение доверия посредством предельной точности
Поскольку системы искусственного интеллекта все больше интегрируются в жизненно важные аспекты бизнеса и общества, стремление к оптимальной точности становится все более насущным, особенно в критически важных приложениях. Используя эти подходы к принятию решений на основе ИИ, основанные на схемах, мы можем создавать системы, которые не только эффективно масштабируются, но и завоевывают глубокое доверие, которое возникает только при стабильной и надежной работе. Будущее не за более мощными индивидуальными моделями, а за тщательно спроектированными системами, сочетающими множественные перспективы со стратегическим человеческим контролем.
Подобно тому, как цифровая электроника прошла путь от ненадежных компонентов до компьютеров, которым мы доверяем самые важные данные, системы искусственного интеллекта сейчас находятся на схожем пути. Описанные в этой статье фреймворки представляют собой чертежи того, что в конечном итоге станет стандартной архитектурой для критически важных систем искусственного интеллекта — систем, которые не только обещают надежность, но и математически гарантируют ее. Вопрос уже не в том, сможем ли мы создать системы ИИ с почти идеальной точностью, а в том, насколько быстро мы сможем внедрить эти принципы в наши самые важные приложения.
Комментарии закрыты.