

Оценка производительности очищенных моделей DeepSeek-R1 на GPQA с использованием Ollama и простых вычислений из OpenAI
Настройте и запустите тест GPQA-Diamond на локально обработанных моделях DeepSeek-R1, чтобы оценить их возможности вывода.
Запуск последней модели ДипСик-Р1 Широкий резонанс в мировом сообществе ИИ. Он добился прорывов, сопоставимых с моделями вывода Meta и OpenAI, и сделал это за гораздо меньшее время и с гораздо меньшими затратами.
Но как, помимо заголовков и интернет-шумихи, мы можем оценить возможности вывода модели, используя общепризнанные критерии? Это важный вопрос для экспертов по ИИ.
Пользовательский интерфейс Deepseek Это упрощает изучение его возможностей, но его программное использование обеспечивает более глубокое понимание и более плавную интеграцию в реальные приложения. Понимание того, как эти модели работают локально, также обеспечивает улучшенный контроль и автономный доступ.

В этой статье мы рассмотрим, как использовать Оллама и simple-evals от OpenAI Оценить возможности вывода очищенных моделей DeepSeek-R1 на основе эталонного теста GPQA-Алмаз Этот критерий считается одним из важнейших инструментов оценки моделей искусственного интеллекта в области логических рассуждений.
Тебе Ссылка на репозиторий GitHub Прилагаем эту статью.
(1) Каковы модели рассуждения?
Модели вывода, такие как DeepSeek-R1 и модели серии o компании OpenAI (например, o1, o3), представляют собой большие языковые модели (LLM), обученные с использованием обучения с подкреплением для выполнения вывода. Эти модели представляют собой передовые инструменты в области искусственного интеллекта, представляющие собой вершину эволюции способности машин мыслить логически и решать сложные задачи.
Эвристика характеризуется глубоким размышлением перед ответом, созданием длинной серии внутренних мыслей перед ответом. Он отлично подходит для решения сложных задач, программирования, научного обоснования и многоэтапного планирования рабочих процессов агентов. Эти возможности делают их незаменимыми в таких областях, как разработка передового программного обеспечения, научные исследования и автоматизация сложных процессов.
(2) Что такое модель DeepSeek-R1?
DeepSeek-R1 — это современная модель большого языка с открытым исходным кодом (LLM), специально разработанная для Расширенное рассуждение. Представлено в январе 2025 г. в исследовательской работе DeepSeek-R1: повышение эффективности выводов в больших языковых моделях с помощью обучения с подкреплением . DeepSeek-R1 — новаторская модель в области искусственного интеллекта.
Эта модель основана на архитектуре большой языковой модели (LLM) с 671 миллиардом параметров и была обучена с использованием обширного обучения с подкреплением (RL) по следующему пути:
- Два этапа аугментации направлены на выявление улучшенных моделей мышления и приведение их в соответствие с предпочтениями человека.
- Два этапа контролируемой тонкой настройки служат зародышем для возможностей вывода и невывода модели.
Для иллюстрации DeepSeek обучил две модели:
- Первая модель, DeepSeek-R1-Zero, представляет собой модель вывода, обученную с использованием обучения с подкреплением, и генерирует данные для обучения второй модели, ДипСик-Р1.
- Это достигается путем создания трассировок вывода, из которых сохраняются только высококачественные выходные данные на основе их конечных результатов.
- Это означает, что в отличие от большинства моделей примеры обучения с подкреплением (RL) в этом конвейере обучения не курируются людьми, а генерируются самой моделью.
В результате модель достигла показателей, аналогичных показателям ведущих моделей, таких как Модель o1 OpenAI В таких задачах, как математика, программирование и сложные рассуждения.
(3) Понимание процесса дистилляции и дистиллированных моделей из DeepSeek-R1
В дополнение к полной модели они также открыли исходный код шести меньших плотных моделей (также называемых DeepSeek-R1) разных размеров (1.5B, 7B, 8B, 14B, 32B, 70B), созданных на основе DeepSeek-R1. Qwen Или Лама В качестве базовой модели.
Дистилляция Это метод, при котором меньшая модель («ученик») обучается воспроизводить работу более крупной и мощной модели, которая была ранее обучена («учитель»).
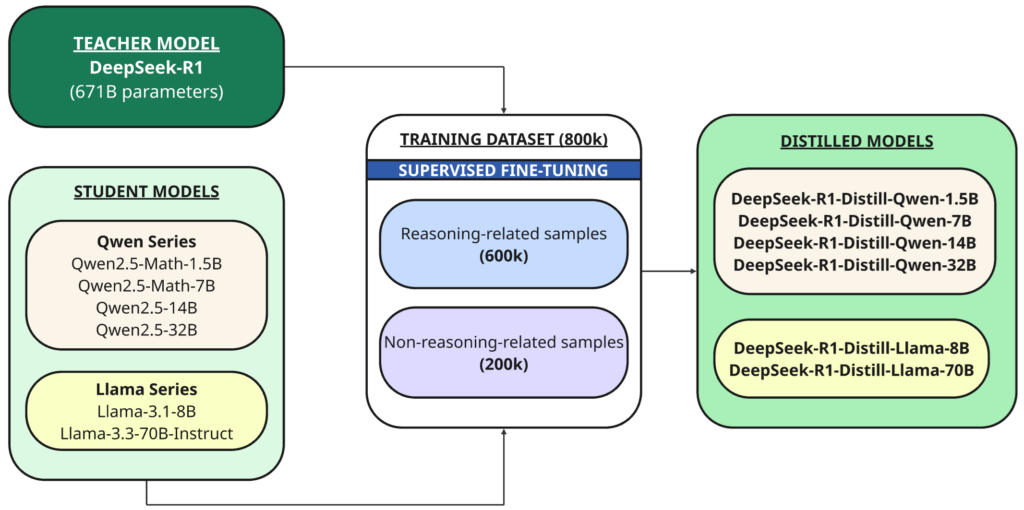
В данном случае учителем является модель 1B DeepSeek-R671, а учениками — шесть моделей, созданных с использованием этой базовой модели с открытым исходным кодом:
- Qwen2.5 — Математика-1.5B
- Qwen2.5 — Математика-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Лама-3.1 — 8Б
- Лама-3.3 — 70Б-Инструкт
DeepSeek-R1 использовался в качестве модели-учителя для генерации 800,000 XNUMX обучающих выборок, смеси выборок с выводом и без вывода, для дистилляции посредством контролируемая тонкая настройка Для базовых моделей (1.5B, 7B, 8B, 14B, 32B и 70B).
Так почему же мы вообще занимаемся дистилляцией?
Цель состоит в том, чтобы перенести возможности вывода более крупных моделей, таких как DeepSeek-R1 671B, на более мелкие и эффективные модели. Это позволяет более мелким моделям справляться со сложными задачами вывода, работая при этом быстрее и эффективнее используя ресурсы.
Кроме того, DeepSeek-R1 имеет огромное количество параметров (671 миллиард), что затрудняет его запуск на большинстве потребительских устройств.
Даже самого мощного MacBook Pro с максимальным объемом объединенной памяти 128 ГБ недостаточно для работы модели с параметрами 671 миллиард.
Таким образом, дистиллированные модели открывают возможность их развертывания на устройствах с ограниченными вычислительными ресурсами.
достигнуто Неленивый Замечательное достижение: исходная модель DeepSeek-R1 с 671 миллиардом параметров была квантована всего до 131 ГБ — впечатляющее сокращение размера на 80%. Однако требование к объему видеопамяти в 131 ГБ остается существенным препятствием, особенно для разработчиков, работающих на устройствах с ограниченными ресурсами. Это достижение представляет собой значительный шаг на пути к тому, чтобы сделать крупные модели ИИ доступными для более широкого круга пользователей.
(4) Выбор оптимальной дистиллированной модели
Учитывая, что на выбор предлагается шесть моделей дистиллятов различных размеров, выбор подходящей модели во многом зависит от возможностей вашего местного оборудования.
Для владельцев высокопроизводительных графических процессоров или центральных процессоров, которым нужна максимальная производительность, идеальным вариантом станут более крупные модели DeepSeek-R1 (32B и выше) — подойдет даже квантовая версия 671B.
Однако, если ресурсы ограничены или вы предпочитаете более быструю сборку (как я), лучшим вариантом будут меньшие дистиллированные варианты, такие как 8B или 14B. Это позволяет сбалансировать производительность и требования к ресурсам.
Для этого проекта я буду использовать усовершенствованную модель DeepSeek-R1. Квен-14Б, что соответствует аппаратным ограничениям, с которыми вы столкнулись. Эта модель (14B) представляет собой отличный компромисс между точностью и скоростью, что делает ее идеально подходящей для моей среды разработки.
(5) Критерии оценки способности делать выводы на основе больших языковых моделей
Большие языковые модели (LLM) обычно оцениваются с использованием стандартизированных показателей, которые определяют их эффективность при выполнении различных задач, включая понимание языка, генерацию кода, выполнение инструкций и ответы на вопросы. Распространенными примерами являются такие показатели, как: ММЛУ, и HumanEval, и МГСМ. Эти показатели необходимы для оценки возможностей больших языковых моделей.
Чтобы измерить способность большой языковой модели рассуждать, нам нужны более сложные тесты, которые в значительной степени фокусируются на рассуждениях и выходят за рамки поверхностных задач. Вот несколько распространенных примеров, которые направлены на оценку продвинутых способностей к рассуждению:
(i) Экзамен AIME 2024: Конкурсная математика
- Подготовить Американский пригласительный экзамен по математике (AIME) 2024 Надежный тест для оценки возможностей больших языковых моделей (LLM) в математических рассуждениях.
- Этот экзамен представляет собой серьезную задачу по спортивной математике, поскольку в нем представлены сложные многошаговые задачи. Экзамен проверяет способность больших языковых моделей понимать сложные вопросы, применять сложные рассуждения и выполнять точные символьные манипуляции. Тест AIME является важным средством оценки навыков решения сложных математических задач.
(ii) Codeforces – Кодекс соревнований
- вставать Стандарт Codeforces Оценка способности к выводу большой языковой модели (LLM) с использованием реальных задач конкурентного программирования с Codeforces, платформы, известной своими алгоритмическими задачами. Codeforces — золотой стандарт оценки возможностей моделей ИИ по решению сложных задач.
- Эти задачи проверяют способность большой языковой модели (LLM) понимать сложные инструкции, выполнять логические и математические рассуждения, планировать многошаговые решения и генерировать правильный и эффективный код. Эти проблемы требуют глубокого понимания алгоритмов и структур данных, а также умения перевести проблему в исполняемый код.
(iii) GPQA Diamond – научные вопросы уровня доктора наук
- GPQA-Diamond — это выбранное подмножество Самые сложные вопросы Из стандарта GPQA (ответы на вопросы по физике для аспирантов) Самый широкий и специально разработанный для того, чтобы расширить границы возможностей моделей LLM делать выводы по продвинутым темам уровня доктора наук. Этот стандарт представляет собой реальный вызов способности ИИ понимать и выводить сложные научные концепции.
- В то время как GPQA включает в себя набор концептуальных и расчетных вопросов для аспирантов, GPQA-Diamond выделяет только самые сложные вопросы и те, которые требуют интенсивного рассуждения.
- Этот критерий считается «устойчивым к Google», то есть на него трудно ответить даже при неограниченном доступе к Интернету. Это делает его ценным инструментом для оценки способности больших языковых моделей рассуждать независимо.
- Вот пример вопроса GPQA-Diamond:
### GPQA Diamond — пример вопроса (молекулярная биология) Эукариотическая клетка выработала механизм превращения макромолекулярных строительных блоков в энергию. Этот процесс происходит в митохондриях, которые являются фабриками клеточной энергии. В серии окислительно-восстановительных реакций энергия из пищи сохраняется между фосфатными группами и используется как универсальная клеточная валюта. Молекулы, богатые энергией, выводятся из митохондрий и используются во всех клеточных процессах. Вы открыли новый препарат для лечения диабета и хотите исследовать, оказывает ли он влияние на митохондрии. Вы провели ряд экспериментов с вашей клеточной линией HEK293. Какой из экспериментов, перечисленных ниже, не поможет вам раскрыть митохондриальную роль вашего препарата: (A) Дифференциальное центрифугирование экстракции митохондрий с последующим набором для колориметрического анализа поглощения глюкозы (B) Проточная цитометрия после мечения 2.5 мкМ 5,5',6,6'-тетрахлор-1,1',3,3'-тетраэтилбензимидазолилкарбоцианин иодида (C) Трансформация клеток рекомбинантной люциферазой и показания люминометра после добавления 5 мкМ люциферина к супернатанту (D) Конфокальная флуоресцентная микроскопия после окрашивания клеток Mito-RTP
В этом проекте В качестве стандарта для заключения мы используем GPQA-Diamond., как я его использовал OpenAI и DeepSeek Оценить их модели вывода. Выбор GPQA-Diamond в качестве стандарта оценки свидетельствует о его сложности и важности в области разработки ИИ.
(6) Используемые инструменты
В этом проекте мы в основном используем Оллама и простые-оценки Из OpenAI. Ollama — это мощная платформа для локального запуска больших языковых моделей, а simple-evals предоставляет фреймворк для оценки производительности этих моделей.
(i) Оллама
Оллама Это инструмент с открытым исходным кодом, который упрощает запуск больших языковых моделей (LLM) на нашем компьютере или на локальном сервере. Olama — идеальная платформа для локального запуска моделей ИИ.
Он действует как менеджер и среда выполнения, выполняя такие задачи, как загрузка и настройка среды. Это позволяет пользователям взаимодействовать с этими моделями без необходимости постоянного подключения к Интернету или использования облачных сервисов. Управление локальными большими языковыми моделями (LLM) является основной функцией Olama.
Он поддерживает множество крупных языковых моделей с открытым исходным кодом, включая DeepSeek-R1, и совместим с macOS, Windows и Linux. Кроме того, он обеспечивает простую настройку с минимальными усилиями и эффективное использование ресурсов. Ollama позволяет вам использовать возможности искусственного интеллекта прямо на вашем устройстве.
ВажныйУбедитесь, что на вашем локальном компьютере есть: Доступность графического процессора Для Ollama это значительно повышает производительность и делает последующее тестирование более эффективным по сравнению с CPU. Выполните команду
nvidia-smiВ терминале проверьте, обнаружен ли графический процессор. Эта процедура гарантирует максимальное использование возможностей устройства для эксплуатации моделей с высокой эффективностью.
(ii) Библиотека OpenAI simple-evals для оценки языковых моделей
Подготовить простые-оценки Облегченная библиотека, предназначенная для оценки языковых моделей с использованием методологии нулевой оценки с подсказками в виде цепочки мыслей. Эта библиотека включает в себя популярные оценочные тесты, такие как MMLU, MATH, GPQA, MGSM и HumanEval, и направлена на моделирование реальных сценариев использования для оценки производительности моделей ИИ при решении сложных задач вывода.
Некоторые из вас, возможно, знакомы с самой популярной и всеобъемлющей библиотекой оценки OpenAI, которая называется Эвалс, что отличается от простых оценок.
На самом деле, страница указывает README Спецификация simple-evals указывает, что она не предназначена для замены библиотеки. Эвалс.
Итак, почему мы используем простые оценки?
Простой ответ заключается в том, что простые-оценки В комплект поставки входят встроенные тексты для оценки стандартов вывода, на которые мы ориентируемся (например, GPQA), которых в библиотеке нет. Эвалс.
Кроме того, я не нашел никаких других инструментов или платформ, кроме simple-evals, которые обеспечивали бы прямой и естественный путь в языке. Питон Соблюдать многие основные стандарты, такие как GPQA, особенно при работе с Ollama.
(7) Результаты оценки
В рамках оценки я выбрал: 20 случайных вопросов Из набора вопросов GPQA-Diamond, состоящего из 198 вопросов для работы Форма 14Б Дистиллятор. В общей сложности это заняло 216 минут, или примерно 11 минут на вопрос.
Результат оказался несколько разочаровывающим, так как он зафиксировал 10%. Только это значительно ниже заявленного результата в 73.3% для модели 1B DeepSeek-R671.
Основная проблема, которую я заметил, заключается в том, что во время интенсивных внутренних рассуждений Модель часто либо не могла дать никакого ответа (например, возвращая коды вывода в качестве конечных строк вывода), либо давала ответ, который не соответствовал ожидаемому формату множественного выбора (например, ответ: A).
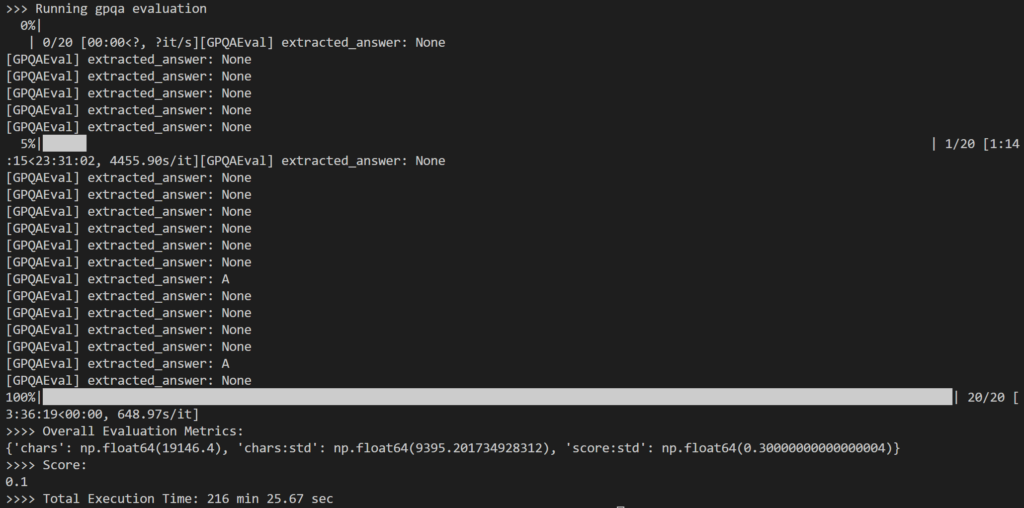
Как показано выше, многие результаты оказались следующими: None Потому что логика регулярных выражений в simple-evals не смогла обнаружить ожидаемый шаблон ответа в ответе LLM.
Пока это рассуждения, подобные человеческим Было интересно наблюдать, так как я ожидал более высоких результатов с точки зрения точности ответов на вопросы.
Я также видел, как пользователи в Интернете упоминали, что даже более крупная модель 32B работает не так хорошо, как o1. Это вызвало сомнения относительно полезности моделей вывода, особенно когда они с трудом дают правильные ответы, несмотря на то, что генерируют длинные выводы.
Однако GPQA-Diamond — очень требовательный тест, поэтому эти модели могут быть полезны для более простых задач вывода. Более низкие вычислительные требования также облегчают задачу.
Кроме того, команда DeepSeek рекомендовала проводить несколько тестов и усреднять результаты в рамках процесса сравнительного анализа — то, что я упустил из виду из-за ограничений по времени.
(8) Подробное пошаговое руководство
До этого момента мы рассмотрели основные концепции и основные выводы.
Если вы готовы к практическому техническому опыту, в этом разделе вы найдете подробный обзор внутренних механизмов и пошаговую реализацию. Это практическое техническое руководство предоставит вам полное представление о том, как работает система.
Для просмотра (или копирования) Сопутствующий репозиторий GitHub Чтобы следовать. Требования к настройке виртуальной среды можно найти здесь. здесь.
(i) Начальная настройка – Оллама
Начнем с загрузки Ollama. Посещать
Страница загрузки Оллама, выберите свою операционную систему и следуйте соответствующим инструкциям по установке.
После завершения установки запустите Ollama, дважды щелкнув приложение Ollama (для Windows и macOS) или выполнив команду ollama serve В терминале.
(ii) Начальная настройка – OpenAI simple-evals
Настройка simple-evals относительно уникальна.
В то время как simple-evals позиционирует себя как библиотека, Отсутствие файлов __init__.py В репозитории означает, что он не структурирован как полноценный пакет Python., что приводит к ошибкам импорта после локального клонирования репозитория. Это означает, что это не стандартный пакет Python в том смысле, который обычно используется в разработке программного обеспечения.
Так как он также не опубликован на PyPI и не имеет стандартных файлов упаковки, таких как setup.py Или pyproject.tomlЕго нельзя установить через pip. Это создает определенные трудности для новых разработчиков.
К счастью, мы можем использовать Подмодули Git Как прямое альтернативное решение. Эти модули позволяют включать один репозиторий Git в другой, что упрощает управление зависимостями.
«`html
Подмодуль Git позволяет нам включать содержимое другого репозитория Git в наш проект. Он извлекает файлы из внешнего репозитория (например, simple-evals), но сохраняет их историю отдельно.
Вы можете выбрать один из двух методов (A или B) для извлечения содержимого simple-evals:
(а) Если вы клонируете мой репозиторий проекта
Мой репозиторий проектов уже включает simple-evals Как подмодуль, так что вы можете просто запустить:
git submodule update --init --recursive(б) Если вы добавляете его в недавно созданный проект.
Чтобы вручную добавить simple-evals как подмодуль, выполните следующее:
git submodule add https://github.com/openai/simple-evals.git simple_evalsуведомление: что simple_evals В конце концов (с подчеркивание) очень важно. Он указывает имя папки, используя вместо него дефис (т.е. просто–evals) могут впоследствии привести к проблемам с импортом.
Заключительный шаг (для обоих методов)
После извлечения содержимого репозитория необходимо создать файл. __init__.py Пусто в папке simple_evals Вновь созданный объект можно импортировать как единое целое. Вы можете создать его вручную или использовать следующую команду:
touch simple_evals/__init__.py(iii) Извлечение модели DeepSeek-R1 через Ollama
Следующий шаг — загрузить локально адаптированную модель по вашему выбору (например, 14B) с помощью этой команды:
Список доступных моделей DeepSeek-R1 можно найти на сайте Ollama. здесь. Для лучшей производительности рекомендуется использовать последнюю версию шаблона.
ollama pull deepseek-r1:14b(Четвертое) Укажите настройки
Мы определяем параметры в файле настроек YAML, как показано ниже:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Имя модели (соответствует списку моделей Ollama) MODEL_TEMPERATURE: 0.6 # Установите между 0.5 и 0.7 для DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
Температура модели установлена на 0.6 (По сравнению с типичным значением по умолчанию 0). Это соответствует рекомендациям DeepSeek, которые предполагают диапазон температур от 0.5 до 0.7 (рекомендуется 0.6). Чтобы предотвратить бесконечные повторения или бессвязный вывод. Эта настройка необходима для улучшения качества вывода и обеспечения его согласованности.
Не упустите шанс проверить Уникальные и интересные рекомендации по использованию DeepSeek-R1 – особенно для бенчмарков – для обеспечения оптимальной производительности при использовании моделей DeepSeek-R1.
EVAL_N_EXAMPLES Это параметр, используемый для установки количества вопросов из полного набора из 198 вопросов, используемых при оценке. Этот параметр необходим для корректировки процесса оценки в соответствии с имеющимися ресурсами и конкретными целями тестирования.
(v) Настройка кода сэмплера
Для поддержки языковых моделей на основе Ollama в рамках simple-evals мы создаем специальный класс-оболочку с именем OllamaSampler И держи это внутри. utils/samplers/ollama_sampler.py. Сэмплер является важнейшим компонентом тестирования и оценки производительности языковых моделей.
# utils/samplers/ollama_sampler.py импорт класса ollama OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = температура def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
В данном контексте это означает пробоотборник (Усилитель) Класс Python, который генерирует вывод из языковой модели на основе заданного приглашения. Этот инструмент имеет решающее значение для обеспечения получения на основе модели разнообразных и репрезентативных ответов.
Поскольку семплеры в simple-evals охватывают только таких поставщиков, как OpenAI и Claude, нам нужен класс семплера, который предоставляет интерфейс, совместимый с Ollama. Это обеспечивает бесшовную интеграцию с системой оценки.
вставать OllamaSampler Извлекает подсказку вопроса GPQA, отправляет ее в форму при указанной температуре и возвращает ответ в виде простого текста. Температура является важным параметром, контролирующим случайность выходных данных.
Метод включен _pack_message Чтобы гарантировать, что формат вывода соответствует тому, что ожидают сценарии оценки в simple-evals. Это обеспечивает последовательность и простоту анализа.
6. Создайте сценарий оценки
Следующий код демонстрирует, как настроить реализацию оценки в файле. main.py, включая использование категории GPQAEval Из библиотеки simple-evals для запуска тестирования производительности GPQA.
Функция run_eval() Это настраиваемый инструмент оценки времени выполнения, который тестирует большие языковые модели (LLM) через Ollama на соответствие таким стандартам, как GPQA. Эта функция необходима для точной оценки производительности моделей.
# main.py def run_eval(): start_time = time.time() # Загрузка файла конфигурации config = load_config("config/config.yaml") # Инициализация сэмплера Ollama (обертка вокруг чата Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Выбор класса оценки для использования на основе EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Запуск оценки {eval_benchmark}") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # По умолчанию 1 "num_examples": config["EVAL_N_EXAMPLES"], # Установить 20 "variant": config["GPQA_VARIANT"], # подмножество GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Создать экземпляр и запустить соответствующий eval evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Выполнить оценку с помощью сэмплера end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Вычислить общее затраченное время # Возвращенные результаты — это EvalResult, который включает список SingleEvalResult и агрегированные метрики print(">>>> Общие метрики оценки:", results.metrics) print(">>>> Оценка:", results.score) print(f">>>> Общее время выполнения: {int(minutes)} min {seconds:.2f} sec") if __name__ == "__main__": # Запустить выполнение оценки GPQA run_eval()
Функция загружает настройки из файла конфигурации, устанавливает соответствующий класс оценки из simple-evals и запускает модель через единый процесс оценки. Он сохраняется в файле. main.py, который можно выполнить с помощью команды python main.py. Это обеспечивает последовательный и повторяемый процесс оценки.
Выполнив описанные выше шаги, мы успешно настроили и выполнили бенчмарк GPQA-Diamond на очищенной модели DeepSeek-R1. Этот процесс дает ценную информацию о возможностях модели.
Суть
В этой статье мы рассмотрим, как можно объединить такие инструменты, как Ollama и простые вычисления OpenAI, для исследования и оценки моделей, полученных из DeepSeek-R1, уделяя особое внимание Оценка производительности больших языковых моделей.
Очищенные модели могут пока не соответствовать исходной модели с 671 миллиардом параметров по таким сложным тестам вывода, как GPQA-Diamond. Однако это иллюстрирует, как дистилляция может расширить доступ к возможностям вывода больших языковых моделей (LLM). Улучшение доступа к большим языковым моделям Это главная цель в этой области.
Несмотря на более низкую производительность при выполнении сложных задач уровня доктора наук, эти меньшие варианты все же могут быть применимы в менее требовательных сценариях, открывая путь для эффективного локального развертывания на более широком спектре устройств. Это способствует Развертывайте большие языковые модели локально Эффективно.
Комментарии закрыты.