

Искусственный интеллект обманул нас с помощью телефонной игры... и результат оказался шокирующим!
Модели генерации изображений на основе искусственного интеллекта быстро развиваются, однако они по-прежнему часто создают сомнительные изображения. Поскольку легко предположить, что проблема в человеческих подсказках, я решил проверить, будет ли ИИ работать легче, если использовать только подсказки, сгенерированные ИИ. Процесс генерации изображений с помощью искусственного интеллекта, такого как ChatGPT и Gemini, во многом зависит от качества и точности подсказок. Будут ли результаты отличаться при использовании автоматизированных заявок? Вот что мы узнаем в ходе этого эксперимента.
![]()
Практические правила
Когда несколько лет назад появились модели генерации изображений на основе искусственного интеллекта, мы все думали, что это станет сигналом тревоги для всех, кто работает в сфере визуальных медиа. Но это было не так. Несмотря на свою способность создавать высокореалистичные изображения, изображения, созданные с помощью ИИ, часто попадают в неожиданную категорию, особенно если вам нужно что-то более сложное (например, ИИ, как правило, испытывает трудности с созданием изображений рук).
В этой проблеме можно винить либо сами модели ИИ, либо недостатки людей и наши непоследовательные навыки в написании претензий. Естественный способ проверить, кто несет ответственность, — это посмотреть, дают ли модели генерации изображений лучшие результаты, если вы внедряете сгенерированные подсказки.

Может ли ИИ дать нам новый взгляд на исторические моменты?
Чтобы проверить эту гипотезу, я воспользуюсь Gemini для создания серии подсказок, в которых не будет использоваться название объекта или изображения, которое я пытаюсь создать. Это поможет проверить, насколько хорошо ИИ «читает» инструкции. Конечно, все еще существует вероятность того, что модель будет черпать значительную часть вдохновения из данных, на которых она была обучена (особенно при воссоздании существующих изображений), но такова реальность, говорит Янг.
Моим инструментом для создания изображений станет Image Creator от Bing (да, Bing все еще существует), основанный на DALL-E 3. Чтобы протестировать модель, я начну с простых фигур, а затем по мере проведения эксперимента перейду к более сложным изображениям.
Если вы использовали ChatGPT или что-то подобное, вы уже знаете, насколько бесполезными могут быть некоторые из его ответов, и то же самое было с подсказками, которые модель задавала мне во время «бета-тестирования». Поэтому я решил ограничиться 500 символами, чтобы сохранить единообразие подсказок.
Как ИИ обрабатывает простые формы
Начнем с простого квадрата. Я попросил Джемини описать квадрат, не называя его, и он придумал следующее:
Четырехугольник, все стороны которого имеют одинаковую длину. Каждый внутренний угол равен ровно 90 градусам. Это правильный четырёхугольник, у которого противоположные стороны параллельны.
После ввода описания в DALL-E я получил следующие результаты:
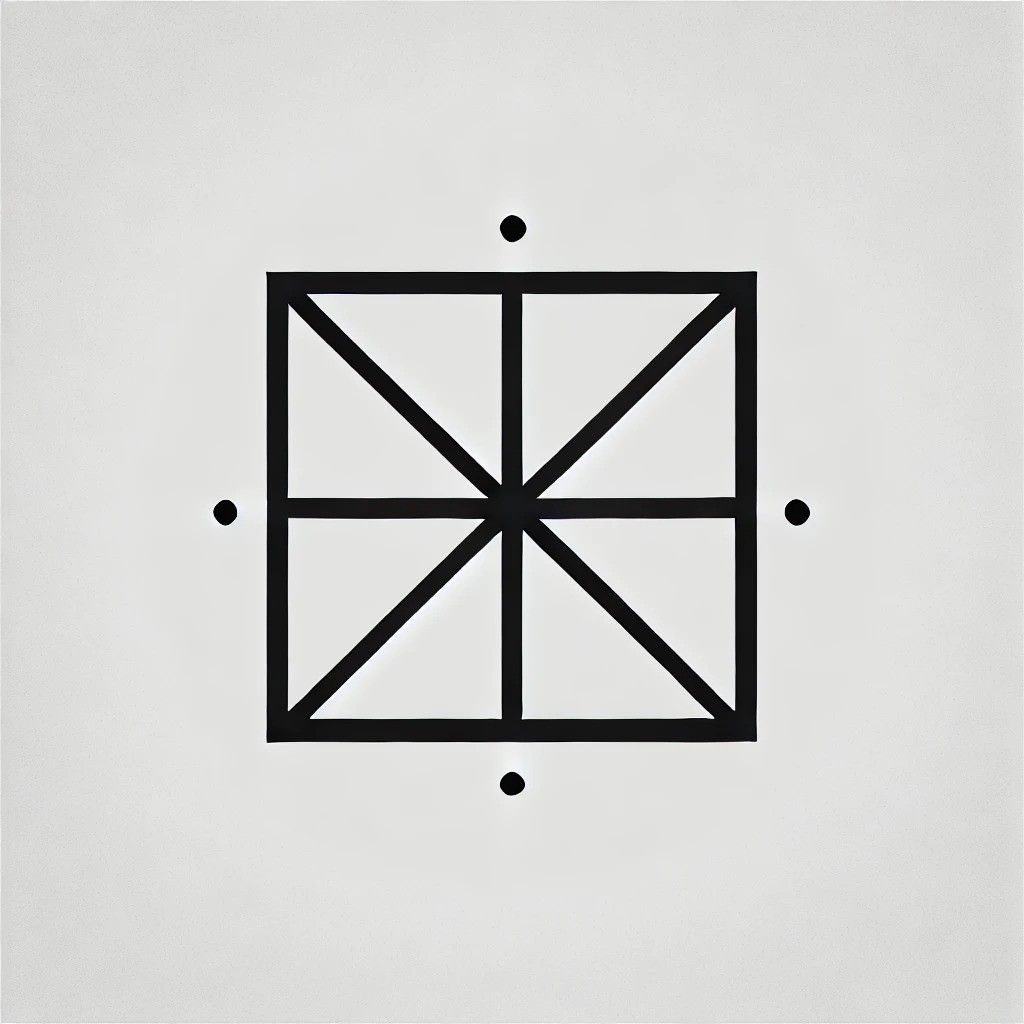
Ладно, это квадрат, хотя, по-моему, это слишком геометрично. Пришло время повысить сложность, поэтому я попросил ИИ детализировать куб.
Трехмерная фигура с шестью совпадающими гранями. Каждая грань представляет собой правильный четырехугольник с четырьмя равными сторонами и четырьмя прямыми углами. Он имеет 12 ребер одинаковой длины и 8 вершин. Все углы внутри фигуры прямые.
Результаты потрясающие:

Помните, что мы говорили о непредсказуемости моделей ИИ? Ну, вот, ДАЛЛ-И создал кубик, но немного запутался и сделал из него кубик Рубика. Несмотря на то, что ИИ полностью избегал точного слова, он частично ошибся — мы можем объяснить это популярностью галактической головоломки.
Взгляд ИИ на фотографию с людьми
Ситуация с кубом показывает, что даже при точном, «беспристрастном» описании ИИ все равно может неверно истолковать довольно простые инструкции. Давайте посмотрим, насколько хорошо он справится с описаниями классических изображений, созданными с помощью искусственного интеллекта, например, с «Матерью-мигранткой» Доротеи Лэнг. Вот оригинальное изображение:

Женщина с выражением беспокойства на лице отворачивается от камеры. Ее окружают дети, их лица скрыты или отвернуты. Ее рука прижата к лицу, выражая усталость и отчаяние. Сцена символизирует нищету и страдания. Одежда женщины потрепанная, а общая композиция мрачная, что подчеркивает серьезность ее положения.
Вот как DALL-E видит знаменитое изображение:

Так близко! Но это не совсем точно, так как DALL-E явно проигнорировал фразу «Ее окружали дети, лица которых были скрыты или отвернуты.Вместо того, чтобы «мать» поднесла руку к лицу, эту роль взял на себя один из детей.
Давайте попробуем что-нибудь посложнее. Возможно, вы видели знаменитую фотографию «Обед на небоскребе»:

«Одиннадцать мужчин сидят на стальной балке высоко над землей и едят свой обед, свесив ноги. Балка висит над раскинувшимся городом. Мужчины выглядят расслабленными, несмотря на экстремальную высоту. Они одеты в деловую одежду, и сцена была снята с немного более низкого ракурса, что подчеркивает высоту».
Это замечательное утверждение дало замечательные результаты:

Если проигнорировать классические маркеры изображений, созданных с помощью ИИ (идентичные горшки и «скопированные и вставленные» объекты), то композиция и общее впечатление от них становятся почти удивительными. Впрочем, это неудивительно — это изображение не только чрезвычайно распространено, но и находится в открытом доступе, поэтому у меня есть смутное подозрение, что DALL-E действительно восстановил свое содержимое во время обучения.
Может ли ИИ обрабатывать сложные изображения?
Поскольку это последний «тест» в эксперименте, пришло время отнестись к делу серьезно! Хотя ИИ хорошо справляется с обработкой изображений людей, он часто терпит неудачу, сталкиваясь со сложными и неоднозначными сценами. А как насчет знаменитой фотографии «Восход Земли», сделанной с лунной орбиты на борту Аполлона-8?

«Частично освещенная сфера висит в темном пространстве. Меньшая, серая сфера поднимается над ее горизонтом. Большая сфера показывает синие и белые пятна, предполагающие воду и облака. Резкий контраст между двумя сферами и чернотой подчеркивает хрупкость и изолированность меньшей, восходящей сферы».
Близнецы (или, скорее, я бы сказал, шар) не подходят под это описание. Поскольку это было слишком абстрактно, я добавил к заявлению фразу «захвачено с окололунной орбиты», но это не сильно помогло:

Это классная обложка альбома в стиле прогрессивного рока, но она не имеет ничего общего с Earthrise. Чтобы завершить эксперимент, я выбрал самое загадочное изображение на данный момент — промышленный шедевр Эдварда Уэстона «Armco Steel»:

«Ряд круглых промышленных металлических резервуаров заполняет кадр. Их формы мягкие и выпуклые, создавая повторяющийся рисунок. Свет отражается от поверхностей, подчеркивая их изогнутые формы и создавая ощущение объема. Композиция фокусируется на абстрактных аспектах промышленных объектов, подчеркивая форму и текстуру, а не функцию. Сцена простая и современная, с сильным акцентом на свет и тень».
Кажется, это хорошая запись, давайте посмотрим, согласится ли с нами Далл-И:

Хоть мне и нравится атмосфера научной фантастики, фильм совершенно не похож на оригинал. Я не хотел заканчивать эксперимент полным провалом, поэтому решил помочь машине, добавив в конец входных данных термин «фотография 1920-х годов».
Я думал, что этот конкретный термин может помочь прояснить картину, которую я имел в виду. К сожалению, Dall-E снова меня разочаровал и сделал обложку еще одного альбома в стиле прогрессивного рока:

Результаты этого эксперимента оказались интересными, и мы можем сделать вывод, что генерация изображений с помощью ИИ крайне непредсказуема, особенно в случае с более абстрактными концепциями. Неважно, являются ли входные данные точными, сгенерированные искусственным интеллектом, или же они созданы человеком и несовершенны — результаты выглядят случайными.
Поэтому в следующий раз, когда вы попытаетесь обвинить себя и свой стиль ввода, помните, что результаты, скорее всего, будут довольно схожими, даже если между собой взаимодействуют два устройства.
Комментарии закрыты.