

Почему большинство моделей рисков кибербезопасности терпят неудачу еще до своего запуска
Необходимость количественного анализа рисков кибербезопасности
Руководители сферы кибербезопасности сталкиваются с неразрешимыми вопросами. «Какова вероятность нарушения безопасности в этом году?» и «Сколько это будет стоить?» и «Сколько нам следует потратить, чтобы это остановить?»
Однако большинство моделей риска, используемых сегодня, по-прежнему основаны на догадках, инстинктах и цветовых картах рисков, а не на данных.
На самом деле, я нашел Глобальное исследование доверия к цифровым технологиям, проведенное PwC в 2025 году Лишь 15% организаций в какой-либо значительной степени используют количественное моделирование рисков.
В этой статье рассматривается, почему традиционные модели рисков кибербезопасности неэффективны и как применение некоторых простых статистических инструментов, таких как вероятностное моделирование, позволяет добиться лучших результатов.

Две основные школы в моделировании киберрисков
Модели киберрисков: Систематические структуры или методы, используемые для анализа, оценки и измерения угроз кибербезопасности и их потенциального воздействия на информационные системы, данные или бизнес.
Специалисты по информационной безопасности в процессе оценки рисков в основном используют два различных метода моделирования рисков: качественный и количественный. Это считается Количественное моделирование киберрисков Продвинутая технология, требующая специальных знаний.
Качественные модели оценки риска
Представьте себе две команды, оценивающие один и тот же риск. Один из них присваивает риску оценку 4/5 по вероятности и 5/5 по воздействию. Другая команда дает ей 3/5 и 4/5. Обе команды находят его на матрице. Но никто из них не может ответить на вопрос финансового директора: «Какова вероятность того, что это действительно произойдет, и во что это нам обойдется?»
Качественный подход основывается на субъективной оценке риска и в основном исходит из интуиции оценщика. Качественный подход обычно приводит к оценке вероятности и воздействия рисков по порядковой шкале, например от 1 до 5.
Далее риски располагаются в матрице рисков, чтобы понять, какое место они занимают на этой порядковой шкале.
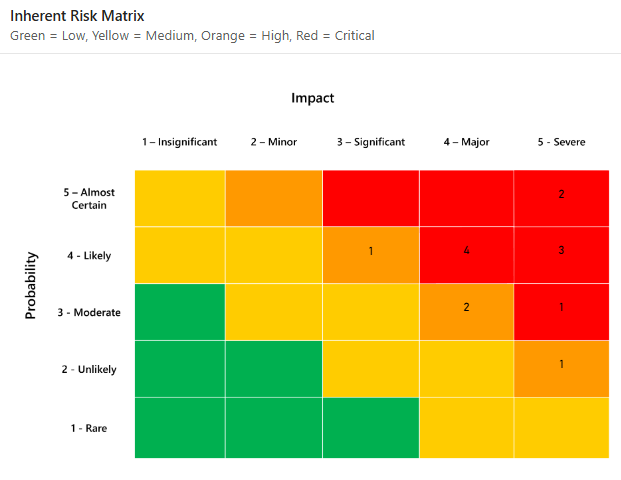
Две порядковые шкалы часто перемножаются, чтобы помочь расставить приоритеты среди наиболее значимых рисков на основе вероятности и воздействия. На первый взгляд это кажется разумным, поскольку общепринятое определение риска в информационной безопасности выглядит следующим образом:
[text{Риск} = text{Вероятность} умножить на text{Влияние}]
Однако со статистической точки зрения качественное моделирование рисков сопряжено с некоторыми весьма существенными рисками.
Первый из этих рисков — использование порядковых шкал. Хотя присвоение чисел порядковой шкале создает видимость математической поддержки модели, это всего лишь иллюзия.
Порядковые шкалы — это просто метки, между ними нет определенного расстояния. Расстояние между риском, имеющим степень воздействия «2», и риском, имеющим степень воздействия «3», не поддается количественной оценке. Изменение обозначений на порядковой шкале на «A», «B», «C», «D» и «E» не имеет значения.
Это, в свою очередь, означает, что наша формулировка риска неверна при использовании качественного моделирования. Невозможно рассчитать вероятность «B», умноженную на эффект «C».
Еще одной серьезной ошибкой является неопределенность моделирования. Когда мы моделируем киберриски, мы моделируем неопределенные будущие события. На самом деле, возможны самые разные результаты.
Сведение киберриска к одноточечным оценкам (например, «20/25» или «высокий») не отражает важное различие между «наиболее вероятные ежегодные потери составляют 1 миллион долларов» и «существует 5%-ная вероятность потери 10 миллионов долларов или более».
Количественное моделирование риска: расширенный анализ
Представьте себе команду, проводящую оценку рисков. Они оценивают диапазон результатов: от 100 10 до 10 миллионов долларов. Проведя моделирование по методу Монте-Карло, они получают 480%-ную вероятность того, что годовые убытки превысят XNUMX миллион долларов, а ожидаемый убыток составит XNUMX XNUMX долларов. Теперь, когда финансовый директор спрашивает: «Насколько вероятно, что это произойдет, и сколько это будет стоить?»Команда может реагировать на данные, а не только интуицию.
Такой подход переводит разговор с неопределенных классификаций рисков на Возможности и потенциальное финансовое воздействие, язык, понятный руководителям.
Если у вас есть опыт работы в области статистики, вам следует обратить особое внимание на одну концепцию:
Вероятность.
Моделирование рисков кибербезопасности по своей сути представляет собой попытку количественно оценить вероятность возникновения определенных событий и последствия, если они произойдут. Это открывает двери для различных статистических инструментов, таких как моделирование по методу Монте-Карло, которое может моделировать неопределенность гораздо эффективнее, чем порядковые меры.
Количественное моделирование риска использует статистические модели для присвоения убыткам денежной стоимости и моделирования вероятности возникновения этих убыточных событий, фиксируя будущую неопределенность.
Хотя качественный анализ иногда может приблизительно определить наиболее вероятный результат, он не в состоянии охватить весь спектр неопределенности, например, редкие, но важные события, известные как «длинный хвостовой риск».
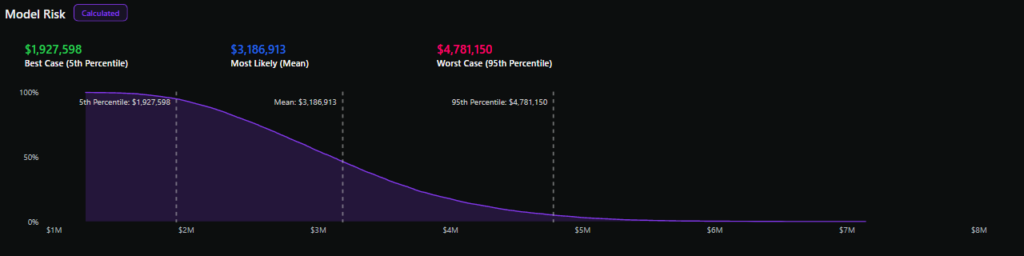
Кривая превышения убытков отображает вероятность превышения заданной суммы годовых убытков по оси Y и различные суммы убытков по оси X, в результате чего получается нисходящая линия.
Используя различные процентные значения из кривой превышения убытков, такие как 90-й процентиль, медиана и XNUMX-й процентиль, можно получить представление о потенциальных годовых убытках для риска с уверенностью XNUMX%.
В то время как одноточечная оценка качественного анализа может приблизительно отражать наиболее вероятные риски (в зависимости от точности суждений оценщиков), количественный анализ фиксирует неопределенность результатов, даже тех, которые редки, но все же возможны (известный как «длиннохвостый риск»).
Взгляд за пределы киберриска: совершенствование моделей риска в кибербезопасности
Чтобы улучшить наши модели рисков в сфере информационной безопасности, нам нужно всего лишь взглянуть вовне, в частности на технологии, используемые в других областях. Модели риска значительно изменились в различных областях применения, таких как финансы, страхование, безопасность полетов и управление цепочками поставок. Эти области предоставляют ценную информацию, которую можно применить в кибербезопасности.
Финансовые команды используют модели для управления рисками инвестиционного портфеля, используя аналогичную байесовскую статистику. В то время как страховые компании моделируют риски, используя сложные актуарные модели. Авиационная отрасль моделирует риск отказа систем с помощью вероятностных моделей. Команды управления цепочками поставок моделируют риски с помощью вероятностного моделирования. Эти методологии обеспечивают прочную основу для разработки эффективных моделей киберрисков.
Инструменты уже существуют. Математические основы хорошо понятны. Другие отрасли промышленности проложили путь. Теперь пришло время для служб кибербезопасности использовать количественные модели риска, чтобы принимать более обоснованные решения, что приведет к улучшению стратегий кибербезопасности и сокращению потенциальных потерь. Внедрение этих количественных моделей представляет собой важный шаг на пути к более эффективному управлению киберрисками.
الخلاصة الرئيسية
| Качественный анализ | Количественный анализ |
| Порядковые шкалы (1-5) | Вероятностное моделирование |
| личная интуиция | статистическая точность |
| Отдельные оценочные баллы | Распределение рисков |
| Тепловые карты и цветовые коды | Кривые превышения потерь |
| Игнорирует редкие, но серьезные события | Улавливает долгосрочный риск |
Комментарии закрыты.