

Пояснение: Как регуляризация L1 автоматически выбирает признаки?
Понять процесс автоматического выбора признаков, выполняемый с помощью регуляризации L1 (LASSO).
Отбор признаков — это процесс выбора оптимального подмножества признаков из заданного набора признаков; Оптимальным подмножеством является то, которое максимизирует производительность модели при решении данной задачи.
Идентификация признаков может быть ручным процессом или довольно явным, если выполняется с использованием методы фильтрации или методы-обертки. В этих методах признаки добавляются или удаляются итеративно на основе значения фиксированной метрики, которая определяет, насколько важен признак для составления прогноза. Метриками могут быть прирост информации, дисперсия или статистика хи-квадрат, а алгоритм примет решение о принятии/отклонении признака с учетом фиксированного порогового значения метрики. Следует отметить, что эти методы не являются частью этапа обучения модели и выполняются до него.
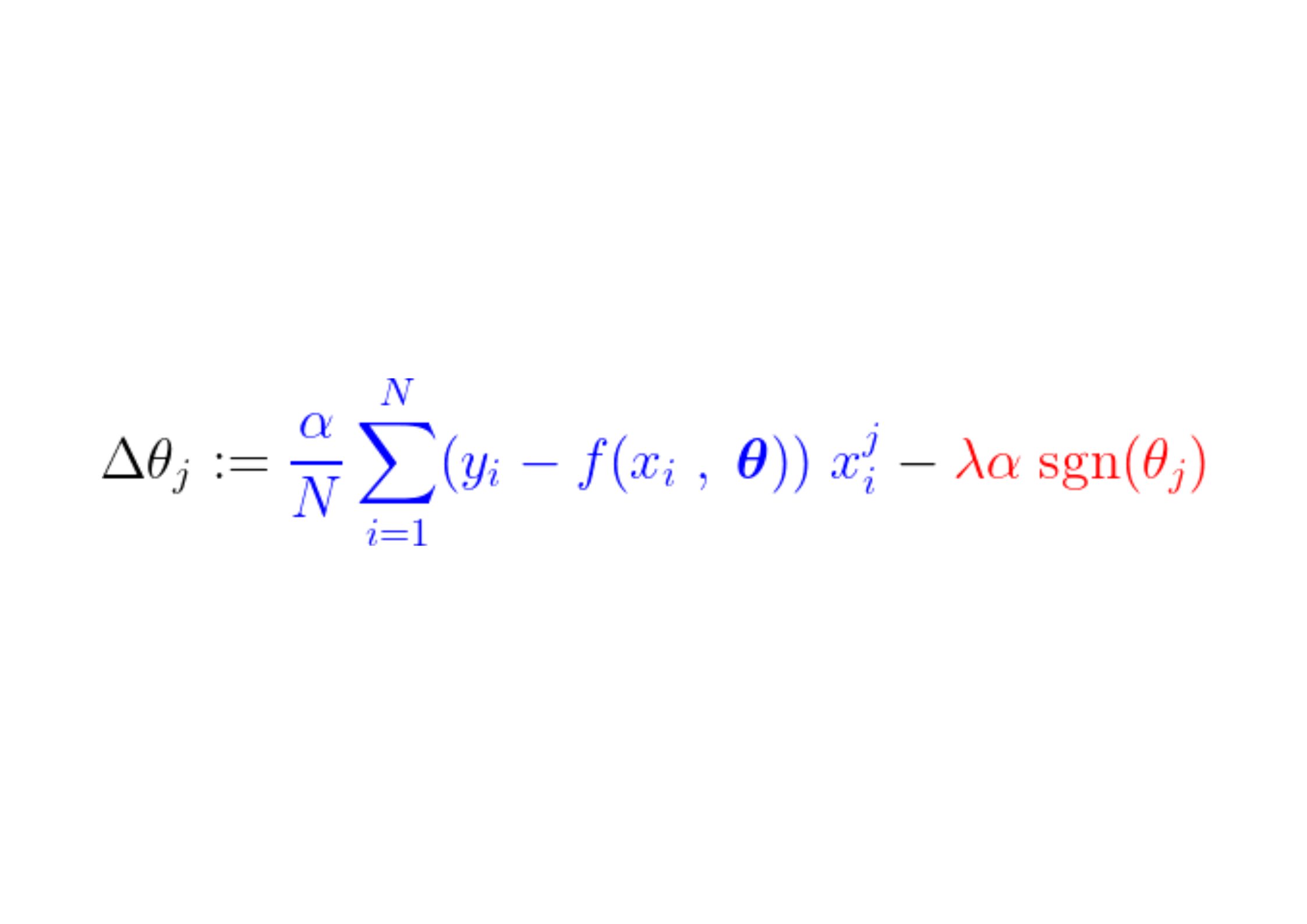
вставать Встроенные методы Путем неявного выбора признаков, без использования каких-либо заранее определенных критериев отбора, и извлечения их из самих обучающих данных. Этот процесс определения основных характеристик является частью этапа обучения модели. Модель учится распознавать особенности и одновременно делать соответствующие прогнозы. В последующих разделах мы опишем роль регуляризации в этом важном процессе выбора признаков, уделив особое внимание регуляризации L1 и ее роли в улучшении моделей машинного обучения.
Нормализация и сложность модели: передовые стратегии повышения производительности
Регуляризация — это процесс снижения сложности модели с целью избежать переобучения и добиться обобщения для поставленной задачи.
Здесь сложность модели аналогична ее способности адаптироваться к закономерностям в обучающих данных. Предполагая простую полиномиальную модель в 'x«в какой-то степени»d«Чем выше оценка»dДля полиномов модель обладает большей гибкостью в выявлении закономерностей в наблюдаемых данных. Такая повышенная гибкость может привести к тому, что модель будет запоминать обучающие данные, а не изучать истинные закономерности, что снизит ее способность к обобщению на новые данные.
Переобучение и недообучение
При попытке подогнать полиномиальную модель со степенью d = 2 На наборе обучающих выборок, полученных из полинома третьего порядка с некоторым шумом, модель не сможет адекватно охватить распределение выборки. В модели просто отсутствует Гибкость Или сложность Требуется для моделирования данных, полученных с помощью полиномов степени 3 (или выше). Говорят, что эта модель неподготовленный На основе данных обучения. Недогрузка указывает на то, что модель слишком проста и не может уловить базовые закономерности в данных.
Работая с тем же примером, мы теперь предполагаем, что у нас есть модель со степенью d = 6. Теперь, с увеличением сложности, модель должна легко оценить исходный кубический полином, который использовался для генерации данных (например, установить коэффициенты всех членов с показателем степени > 3 равными 0). Если процесс обучения не будет завершен вовремя, модель продолжит использовать свою дополнительную гибкость для дальнейшего снижения ошибки и начнет захватывать также и зашумленные образцы. Это значительно уменьшит ошибку обучения, но теперь модель переобувается На основе данных обучения. Шум изменится в реальных условиях (или на этапе тестирования), и любые знания, основанные на прогнозировании, будут нарушены, что приведет к высокой погрешности тестирования. Перегрузка означает, что модель слишком сложна и изучает шум, а не реальный сигнал.
Как определить оптимальную сложность модели?
На практике мы часто имеем ограниченное или не имеем никакого представления о процессе генерации данных или об их истинном распределении. Поиск оптимальной модели с подходящей сложностью, исключающей недообучение или переобучение, представляет собой серьезную задачу. Это требует использования эффективных методов оценки производительности моделей и определения подходящей сложности, которая обеспечивает наилучший баланс между точностью и универсальностью. Используя соответствующие метрики оценки и методы, такие как перекрестная проверка, специалисты могут определить модель, которая лучше всего работает на неизвестных данных, тем самым избегая проблем, связанных с переобучением или недообучением.
Один из возможных методов — начать с достаточно надежной модели, а затем уменьшить ее сложность путем выбора признаков. Чем меньше функций, тем менее сложна модель.
Как мы обсуждали в предыдущем разделе, выбор признаков может быть явным (методы фильтрации, методы свертки) или неявным. Избыточные признаки, которые не очень важны для определения значения целевой переменной, следует удалить, чтобы избежать изучения моделью некоррелированных закономерностей в них. Регуляризация также выполняет аналогичную задачу. Итак, как регуляризация и выбор признаков связаны с достижением общей цели оптимальной сложности модели? Снижение сложности моделей машинного обучения имеет решающее значение для повышения производительности и предотвращения переобучения, на чем и сосредоточены как регуляризация, так и отбор признаков.
Регуляризация L1 как определитель признаков
Продолжая нашу полиномиальную модель, представим ее как функцию f с входными данными xи транзакции θ И степень d،
![]()
Для полиномиальной модели можно рассматривать каждую степень входного сигнала х_я В качестве преимущества можно сформировать вектор следующего вида:
![]()
Мы также определяем целевую функцию, минимизация которой приводит к оптимальным параметрам. θ * Термин включает в себя: регуляризация (Регулирование), которое налагает штрафы за сложность модели.
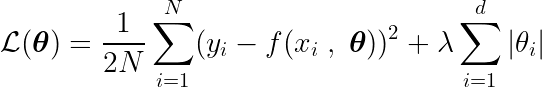
Чтобы найти минимум этой функции, нам необходимо проанализировать все критические точки, то есть точки, где производная равна нулю или не определена.
Частную производную можно записать по одному из параметров: θj, Следующее:
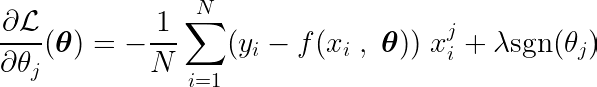
где функция определена SGN Следующим образом:
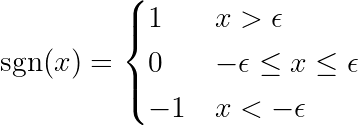
уведомлениеПроизводная абсолютной функции отличается от знаковой функции (sgn), определенной выше. Исходная производная не определена при x = 0. Мы расширяем определение, чтобы удалить точку перегиба при x = 0 и сделать функцию дифференцируемой во всем диапазоне ее значений. Более того, фреймворки машинного обучения (ML) используют эти расширенные функции, когда базовые вычисления включают абсолютную функцию. Посмотрите это! ссылка На форуме PyTorch.
Вычислив частную производную целевой функции по одному коэффициенту θj, и приравняв его к нулю, мы можем построить уравнение, связывающее оптимальное значение θj С прогнозами, целями и особенностями.
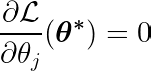
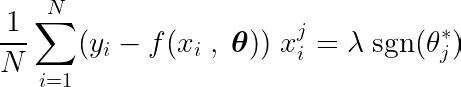
Давайте рассмотрим приведенное выше уравнение. Предполагая, что входные данные и цели были сосредоточены вокруг среднего значения (т. е. данные были стандартизированы на этапе предварительной обработки), член в левой части (LHS) фактически представляет дисперсия Между номером признака j и разницей между ожидаемым и целевым значениями.
Статистическая ковариация между двумя переменными определяет степень влияния одной переменной на значение второй переменной (и наоборот).
Функция знака в правой части заставляет вариацию в левой части принимать только три значения (поскольку функция знака возвращает только -1, 0 и 1). Если функция j Ненужно и не влияет на прогнозы, дисперсия будет близка к нулю, делая соответствующий коэффициент θj* Ноль. В результате элемент удаляется из модели. Этот процесс помогает снизить сложность и улучшить производительность модели.
Представьте себе функцию знака как канавку, прорезанную водой. Вы можете войти в овраг (т. е. русло реки), но чтобы выбраться из него, вам придется столкнуться с огромными препятствиями или крутыми порогами. Регуляризация L1 создает «пороговый» эффект, аналогичный градиенту функции потерь. Градиент должен быть достаточно сильным, чтобы преодолеть барьеры или стать нулевым, в конечном итоге сделав значение коэффициента нулевым.
Чтобы привести более реалистичный пример, рассмотрим набор данных, содержащий выборки, полученные из прямой линии (двухфакторная параметризация) с некоторым добавленным шумом. Оптимальная модель не должна иметь более двух параметров, в противном случае она будет переобучен шуму в данных (с учетом дополнительной свободы/степени полинома). Изменение коэффициентов более высокой мощности в полиномиальной модели не влияет на разницу между целевыми значениями и прогнозами модели и, таким образом, уменьшает их дисперсию с признаком.
В процессе обучения к градиенту функции потерь добавляется/вычитается фиксированный шаг. Если градиент функции потерь (MSE – средняя квадратическая ошибка) меньше постоянного шага, коэффициент в конечном итоге достигнет значения 0. Обратите внимание на уравнение ниже, которое показывает, как коэффициенты обновляются с использованием градиентного спуска:

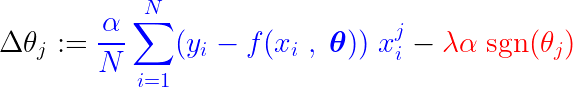
Если синяя часть выше меньше, чем Ла, что само по себе является очень малым числом, то Δθj Это почти уверенный шаг. Ла. Сигнал для этого шага (красная часть) зависит от: sgn(θj), выход которого зависит от θj. Если значение равно θj Положительно, т.е. больше, чем ε, то sgn(θj) равно 1, таким образом делая Δθj Примерно равно -Ла, приближая его к нулю.
Чтобы подавить постоянный шаг (красная часть), делающий коэффициент нулевым, градиент функции потерь (синяя часть) должен быть больше размера шага. Чтобы получить больший градиент для функции потерь, значение признака должно существенно влиять на выходные данные модели.
Таким образом, признак, а точнее, соответствующий ему параметр, значение которого не связано с выходными данными модели, обнуляется регуляризацией L1 во время обучения.
Дальнейшее чтение и заключение
- Чтобы получить больше информации по этой теме, я задал вопрос на Reddit r/MachineLearning, иСледовать за Он содержит различные толкования, с которыми вам, возможно, будет интересно ознакомиться.
- Мадияр Айтбаев также имеет интересный блог Охватывает тот же вопрос, но с инженерным пояснением.
- Блог Брайан Кинг объясняет организацию с вероятностной точки зрения.
- это النقاش На сайте CrossValidated он объясняет, почему критерий L1 поощряет использование разреженных моделей. Блог Подробная статья Мукула Ранджана объясняет, почему норма L1 способствует тому, чтобы транзакции стали нулевыми, а норма L2 — нет.
«Регуляризация L1 выбирает признаки» — простое утверждение, с которым согласны большинство изучающих машинное обучение, не вдаваясь в то, как это работает изнутри. Этот блог — попытка представить читателям мое понимание и ментальную модель, чтобы ответить на вопрос интуитивно. Если у вас есть предложения или сомнения, вы можете обратиться на мою электронную почту по адресу Мой сайт. Продолжайте учиться и желаю вам прекрасного дня!
Комментарии закрыты.