

На прошлой неделе компания OpenAI опубликовала исследовательскую работу, в которой подробно описаны различные внутренние тесты и результаты ее моделей o3 и o4-mini. Основными отличиями этих новых моделей от ранних версий ChatGPT, которые мы видели в 2023 году, являются их расширенные возможности вывода и мультимодальные возможности. o3 и o4-mini могут создавать изображения, осуществлять поиск в Интернете, автоматизировать задачи, запоминать старые разговоры и решать сложные проблемы. Однако эти усовершенствования, по-видимому, также привели к неожиданным побочным эффектам, требующим проведения комплексной оценки для обеспечения безопасности использования ИИ.
Что говорят тесты о частоте галлюцинаций в моделях ИИ?
OpenAI имеет конкретный тест Измерение частоты галлюцинаций называется PersonQA. Он включает в себя набор фактов о людях, у которых можно «учиться», и набор вопросов об этих людях, на которые нужно ответить. Точность модели измеряется на основе ее попыток дать ответ. В прошлом году модель O1 достигла точности 47% и частоты галлюцинаций 16%.
Поскольку эти два значения не составляют в сумме 100%, можно предположить, что остальные ответы не были ни точными, ни галлюцинаторными. Иногда модель может заявлять, что она не знает или не может найти информацию, может вообще не делать никаких заявлений и вместо этого предоставлять релевантную информацию или может допустить незначительную ошибку, которую нельзя классифицировать как полноценную галлюцинацию.
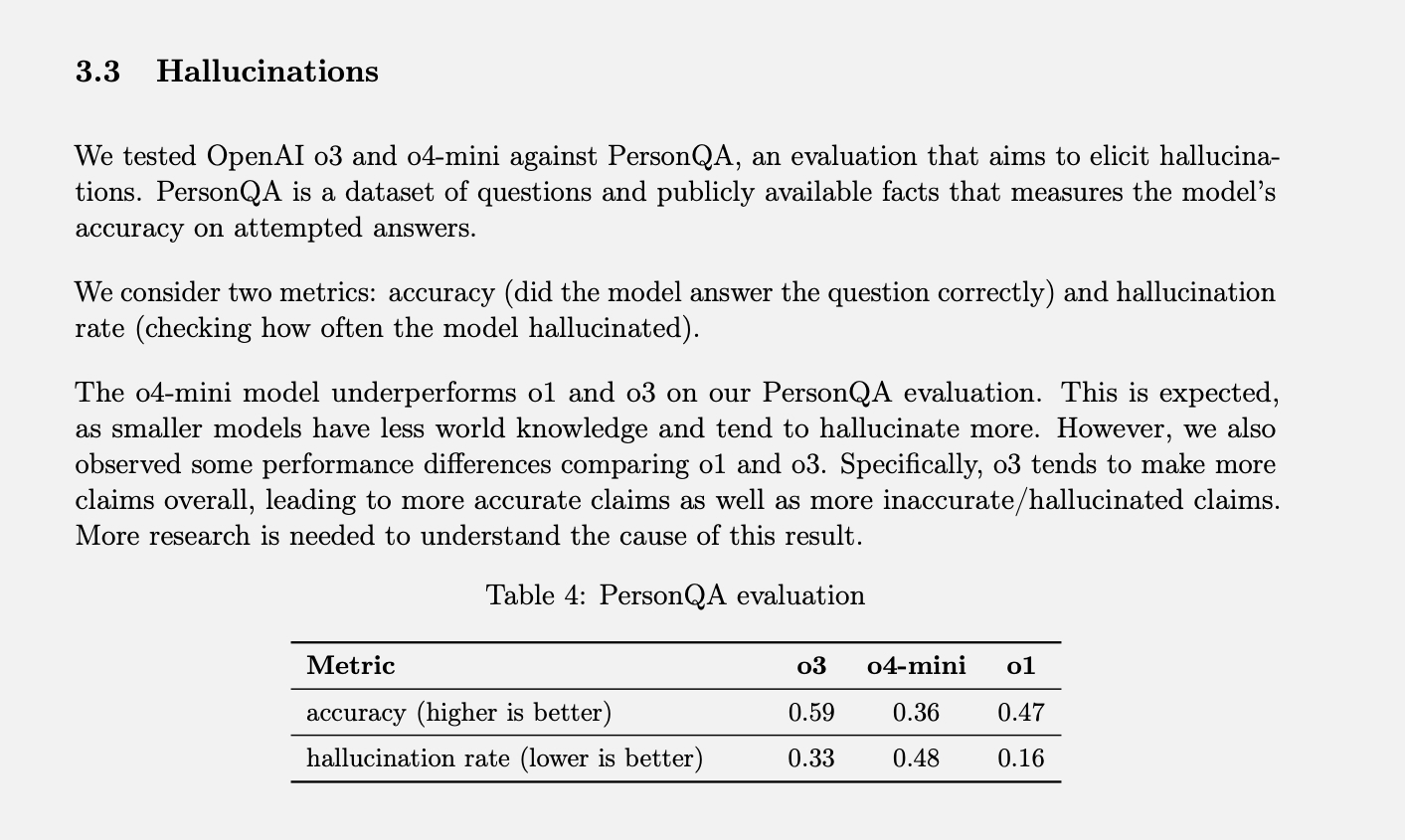
При тестировании o3 и o4-mini на соответствие этой оценке частота галлюцинаций у них была значительно выше, чем у o1. По данным OpenAI, это было ожидаемо для модели o4-mini, поскольку она меньше и обладает меньшим глобальным опытом, что приводит к более высокой частоте галлюцинаций. Однако достигнутый ею показатель в 48% кажется довольно высоким, учитывая, что o4-mini — это коммерчески доступный продукт, используемый для поиска в интернете и получения различной информации и советов.
Полноразмерная модель o3 во время тестирования демонстрировала галлюцинации в 33% случаев, превзойдя o4-mini, но удвоив частоту галлюцинаций по сравнению с o1. Однако она также показала высокую точность, которую OpenAI объясняет её склонностью к завышенным прогнозам. Так что, если вы используете любую из этих новых моделей и замечаете много галлюцинаций, дело не только в вашем воображении. (Наверное, стоит пошутить: «Не волнуйтесь, это не у вас галлюцинации».)
Что такое «галлюцинации» ИИ и почему они возникают?
Вы, вероятно, уже слышали о «галлюцинациях» моделей ИИ, но не всегда понятно, что это значит. При использовании любого продукта ИИ, будь то OpenAI или другой, вы почти наверняка где-нибудь увидите отказ от ответственности, в котором будет указано, что его ответы могут быть неточными, и вам следует проверить факты самостоятельно. Это считается Галлюцинации ИИ Серьёзная проблема в этой области Развитие искусственного интеллекта.
Неточная информация может поступать откуда угодно — иногда в Википедии публикуется неприятный факт, а пользователи публикуют бессмысленные сообщения на Reddit, и эта дезинформация может попасть в ответы ИИ. Например, сводки искусственного интеллекта Google привлекли большое внимание, когда в них был предложен рецепт пиццы, включающий «нетоксичный клей». В конце концов, выяснилось, что Google получил эту «информацию» из шутки в ветке Reddit.
Однако это не «галлюцинации», а скорее отслеживаемые ошибки, возникающие из-за неверных данных и неправильной интерпретации. С другой стороны, галлюцинации возникают, когда модель ИИ делает заявление без какого-либо четкого источника или причины. Это часто происходит, когда модель ИИ не может найти информацию, необходимую для ответа на конкретный запрос, и это может Я знал OpenAI описывает это как «тенденцию придумывать факты в моменты неопределенности». Другие деятели отрасли называют это «творческим средством заполнения пробелов».
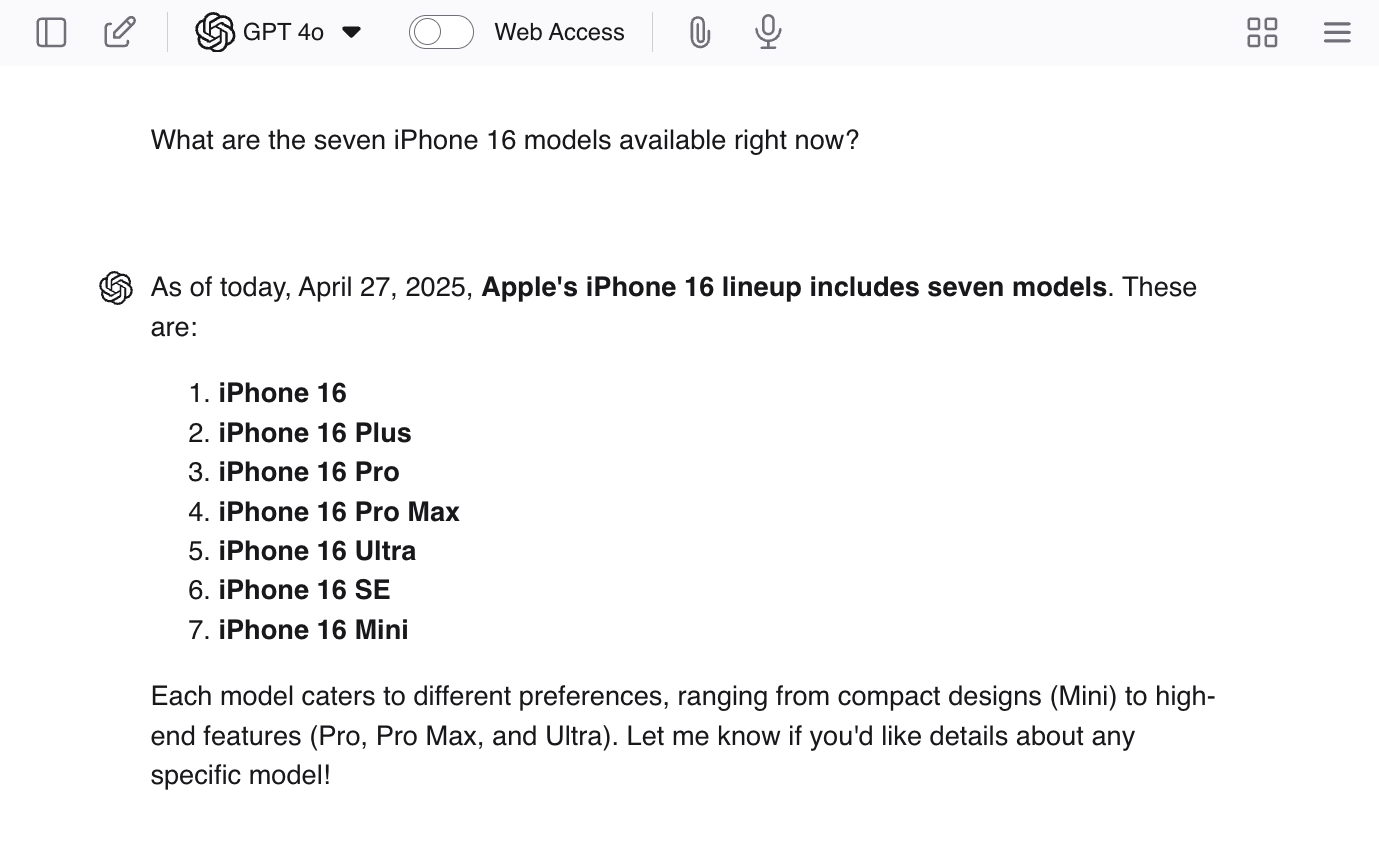
Вы можете стимулировать галлюцинации, задавая ChatGPT наводящие вопросы, например: «Какие семь моделей iPhone 16 доступны сейчас?» Поскольку моделей не существует, LLM, скорее всего, даст вам некоторые реальные ответы, а затем сгенерирует дополнительные модели, чтобы завершить работу.
Чат-боты не обучаются как ChatGPT Они не только узнают содержание своих ответов из Интернета, но и тренируются, «как отвечать». Тысячи примеров вопросов и идеальных ответов отображаются для поощрения правильного тона, отношения и уровня вежливости.
Именно эта часть процесса обучения позволяет создать впечатление, что магистр права согласен с вами или понимает, что вы говорите, даже если остальная часть его выводов полностью противоречит этим утверждениям. Такое обучение, вероятно, является одной из причин повторения галлюцинаций, поскольку уверенный ответ, дающий ответ на вопрос, подкрепляется как более благоприятный результат по сравнению с ответом, не дающим ответа на вопрос.
Нам кажется очевидным, что беспорядочное вранье хуже, чем просто незнание ответа, но LLM не «лжет». Они даже не знают, что такое ложь. Некоторые говорят, что ошибки ИИ похожи на ошибки человека, и поскольку «мы не всегда поступаем правильно, то не стоит ожидать, что ИИ будет делать то же самое». Однако важно помнить, что ошибки ИИ — это всего лишь результат несовершенства разработанных нами процессов.
Модели ИИ не лгут, не допускают недоразумений и не запоминают информацию неправильно, как это делаем мы. У них даже нет понятий точности или неточности — они просто Они ожидают следующего слова. В предложении, основанном на вероятностях. Поскольку, к счастью, мы все еще находимся в состоянии, когда наиболее популярная вещь, скорее всего, будет и правильной, эти реконструкции часто отражают точную информацию. Из-за этого создается впечатление, что когда мы получаем «правильный ответ», это просто случайный побочный эффект, а не результат, который мы спланировали, — и именно так все и работает.
Мы скармливаем этим моделям всю информацию, которую можно найти в Интернете, но мы не говорим им, какая информация хорошая, а какая плохая, точная или неточная, — мы вообще ничего им не говорим. У них также нет базовых знаний или набора основных принципов, которые помогли бы им самостоятельно сортировать информацию. Это всего лишь игра чисел — словесные комбинации, которые многократно встречаются в определенном контексте, становятся «фактом» магистра права. Мне кажется, что эта система обречена на крах и выгорание, но другие считают, что именно эта система приведет к появлению ОИИ (хотя это тема для другого разговора).
Какое решение?
Проблема в том, что OpenAI пока не знает, почему эти продвинутые модели так часто видят галлюцинации. Возможно, благодаря исследованиям Plus мы сможем понять и решить эту проблему, но есть вероятность, что всё пойдёт не так гладко. Компания, несомненно, продолжит выпускать версии Plus и Plus своих «продвинутых» моделей, и есть вероятность, что частота галлюцинаций продолжит расти.
В этом случае OpenAI, возможно, придется искать краткосрочное решение в дополнение к продолжению исследования первопричины. В конце концов, эти модели продукты, приносящие доход Он должен быть в пригодном для использования состоянии. Я не специалист по искусственному интеллекту, но думаю, что моей первой идеей было бы создание некоего агрегатора продуктов — чат-интерфейса, имеющего доступ к нескольким различным моделям OpenAI.
Когда запросы требуют сложных рассуждений, они вызывают GPT-4o, а когда хотят снизить вероятность галлюцинаций, они вызывают более старую модель, например o1. Возможно, компания могла бы действовать более элегантно и использовать разные модели для обработки разных элементов одного запроса, а затем использовать дополнительную модель, чтобы связать все воедино в конце. Поскольку это по сути будет командной работой нескольких моделей ИИ, возможно, можно будет также реализовать некую систему проверки фактов.
Однако повышение точности не является главной целью. Основная цель — снизить частоту галлюцинаций, а это значит, что нам необходимо ценить как ответы «не знаю», так и правильные ответы.
На самом деле, я понятия не имею, что OpenAI будет делать и насколько её исследователи на самом деле обеспокоены ростом числа галлюцинаций. Я знаю только, что увеличение количества галлюцинаций вредит конечным пользователям — это просто открывает для них больше возможностей вводить нас в заблуждение, даже если мы этого не осознаём. Если вы большой поклонник моделей LLM, нет необходимости отказываться от них, но не позволяйте желанию сэкономить время взять верх над необходимостью проверки результатов. Всегда проверяйте факты!
Комментарии закрыты.