

Такие модели рассуждений, как OpenAI o1 и DeepSeek-R1, сталкиваются с проблемой чрезмерного мышления. Если задать ей простой вопрос, например: «Сколько будет 1+1?», она подумает несколько секунд, прежде чем ответить.

В идеале модели ИИ, как и люди, должны уметь определять, когда следует давать прямой ответ, а когда следует выделить дополнительное время и ресурсы на размышления перед ответом. И это так новая технология Представлено исследователями в Мета ИИ وИллинойсский университет в Чикаго Путем обучения моделей распределению бюджетов выводов на основе сложности запроса. Это приводит к более быстрому реагированию, снижению затрат и более эффективному распределению вычислительных ресурсов.
дорогостоящее рассуждение
Большие языковые модели (LLM) могут улучшить свою производительность при решении задач на рассуждение, если они создают более длинные цепочки мыслей, часто называемые «цепочками мыслей» (CoT). Успех метода цепочки идей привел к появлению целого набора методов масштабирования времени вывода, которые заставляют модель глубже «думать» о проблеме, генерировать и рассматривать несколько ответов и выбирать лучший из них.
Большинством голосов (MV) называют один из основных методов, используемых в моделях рассуждений, при котором генерируется несколько ответов и выбирается наиболее часто задаваемый ответ. Проблема этого подхода заключается в том, что модель придерживается единообразного поведения, рассматривая каждый входной сигнал как сложную задачу рассуждения и потребляя ненужные ресурсы для генерации нескольких ответов.
Интеллектуальное рассуждение
В новой исследовательской работе предлагается ряд методов обучения, которые повышают эффективность моделей рассуждений при реагировании. Первый шаг — «последовательное голосование» (ПГ), при котором модель прерывает процесс рассуждения, как только определенный ответ появляется определенное количество раз. Например, в форме предлагается сгенерировать максимум восемь ответов и выбрать тот, который встречается не менее трех раз. Если модели задать простой запрос, приведенный выше, первые три ответа, скорее всего, будут схожими, что приведет к ранней остановке, экономии времени и вычислительных ресурсов.
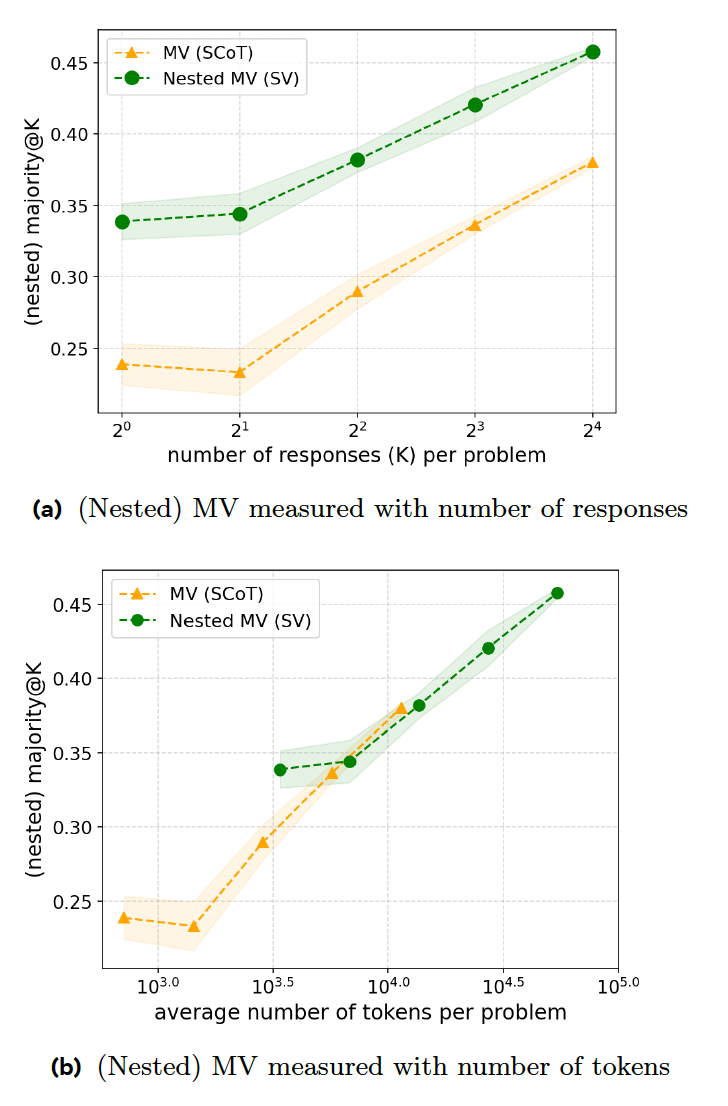
Их эксперименты показывают, что SV превосходит классический MV при решении задач математических соревнований, когда генерирует одинаковое количество ответов. Однако SV требует дополнительных инструкций и генерации кода, что ставит его в один ряд с MV по соотношению кода к точности.
Вторая методика, адаптивное последовательное голосование (ASV), улучшает SV, требуя от модели изучения проблемы и генерации нескольких ответов только в случае сложности проблемы. Для простых задач (например, для претензий 1+1) модель просто генерирует один ответ, не проходя через процесс голосования. Это делает модель более эффективной при решении как простых, так и сложных задач.
Обучение с подкреплением
Хотя методы SV и ASV повышают эффективность модели, они требуют большого объема вручную размеченных данных. Чтобы смягчить эту проблему, исследователи предлагают «оптимизацию политики вывода с ограниченным бюджетом» (IBPO) — алгоритм обучения с подкреплением, который учит модель корректировать длину путей рассуждений в зависимости от сложности запроса.
IBPO разработан для того, чтобы позволить большим языковым моделям (LLM) улучшить свои ответы, оставаясь при этом в рамках ограничений бюджета вывода. Алгоритм обучения с подкреплением позволяет модели превзойти результаты, полученные при обучении на вручную размеченных данных, путем непрерывной генерации траекторий ASV, оценки ответов и выбора результатов, которые обеспечивают правильный ответ и оптимальный бюджет вывода.
Их эксперименты показывают, что IBPO улучшает фронт Парето, а это означает, что при фиксированном бюджете вывода модель, обученная на основе IBPO, превосходит другие базовые показатели.
Эти результаты появились на фоне предупреждений исследователей о том, что существующие модели искусственного интеллекта испытывают трудности. Компании изо всех сил пытаются найти высококачественные данные для обучения и изучают альтернативные способы улучшения своих моделей.
Одним из перспективных решений является обучение с подкреплением, при котором модели задается цель и она может находить собственные решения, в отличие от контролируемой тонкой настройки (SFT), при которой модель обучается на вручную размеченных примерах.
Удивительно, но модель часто находит решения, о которых люди даже не задумывались. Эта формула, судя по всему, сработала с DeepSeek-R1, бросившим вызов доминированию американских лабораторий искусственного интеллекта.
Исследователи отмечают, что «методы, основанные на подсказках, и SFT борются за абсолютную оптимизацию и эффективность, подтверждая гипотезу о том, что SFT сама по себе не обеспечивает возможности самокоррекции. Это наблюдение также подтверждается параллельной работой, которая предполагает, что это самокорректирующееся поведение возникает спонтанно во время RL, а не генерируется вручную с помощью подсказок или SFT».
Комментарии закрыты.