

Улучшение обнаружения в моделях Transformer путем добавления обучающего шума
Современные модели машинного зрения Transformer добавляют шум для улучшения эффективности обнаружения 2D- и 3D-объектов. В этой статье мы узнаем, как работает этот механизм, и обсудим его вклад в повышение точности моделей обнаружения объектов, уделяя особое внимание использованию таких методов, как шумоподавление в процессе обучения.

Модели-трансформеры для раннего зрения
DETR – DEtection TRansformer (Carion, Massa et al. 2020), одна из первых архитектур Transformer для обнаружения объектов, использовала обученные запросы кодировщика-декодера для извлечения информации обнаружения из токенов изображений. Эти запросы инициализировались случайным образом, и Архитектура не накладывала никаких ограничений, которые заставляли бы эти запросы изучать объекты, подобные якорям. Хотя он достиг схожих результатов с Faster-RCNN, его недостатком была медленная сходимость — для его обучения требовалось 500 эпох (DN-DETR, Li et al., 2024). Более поздние архитектуры на основе DETR использовали деформируемое объединение, которое позволяло запросам фокусироваться только на определенных областях изображения (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), в то время как другие (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) использовали пространственные якоря (сгенерированные с использованием k-средних, аналогично тому, как это делают CNN на основе якорей), которые были закодированы в исходных запросах. Пропускные соединения заставляют блок декодера Transformer изучать квадраты как значения наклона от якорей. Деформируемые слои внимания использовали предварительно закодированные якоря для выборки пространственных объектов на изображении и их использования для генерации токенов внимания. В процессе обучения модель усваивает идеальные якоря для использования. Такой подход учит модель явно использовать в своих запросах такие характеристики, как размер блока.
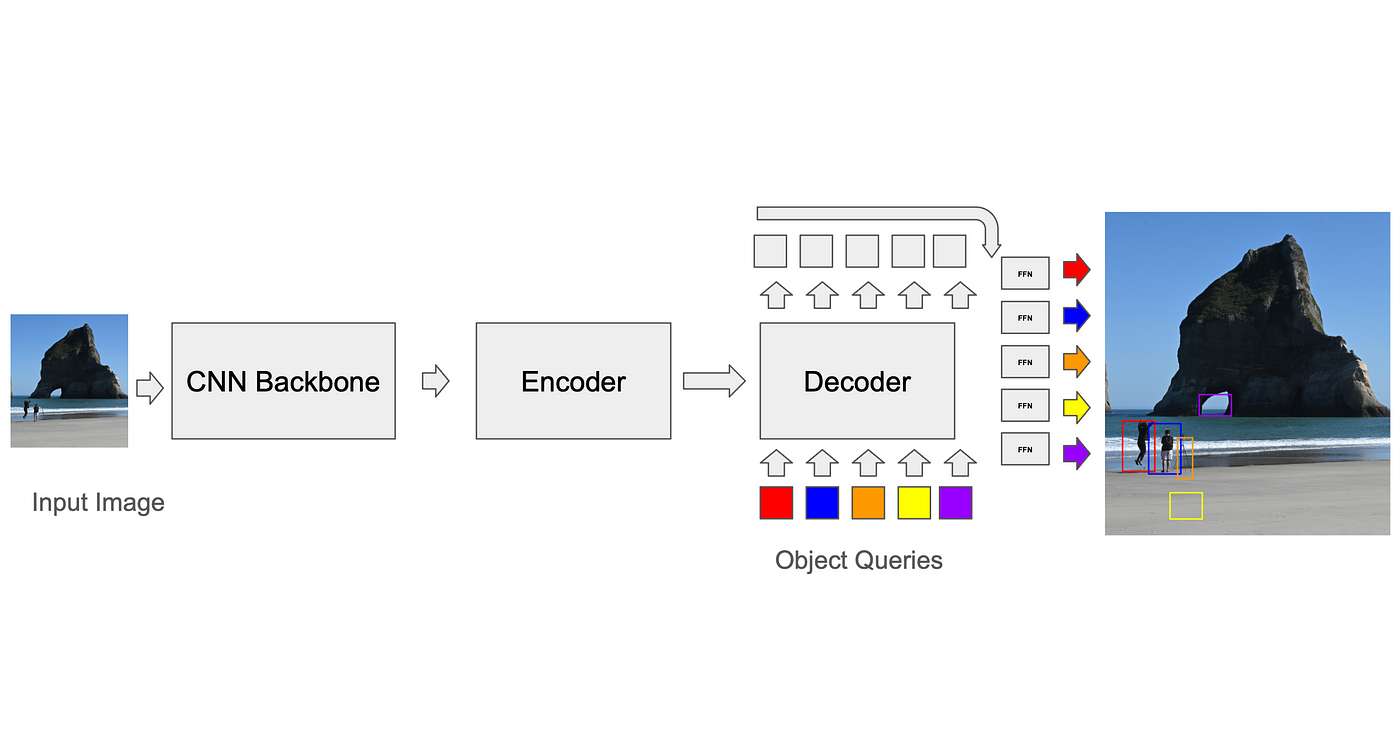
Сопоставление прогнозов с реальными фактами: алгоритм двоичного сопоставления
Чтобы рассчитать потери, тренеру сначала необходимо сопоставить прогнозы модели с истинными данными (GT). В то время как CNN на основе якорей имеют относительно простые решения этой проблемы (например, каждый якорь может быть сопоставлен только с блоками GT в его вокселе во время обучения, а при выводе используется подавление немаксимума для удаления перекрывающихся обнаружений), стандарт для трансформаторов, разработанный DETR, заключается в использовании алгоритма бинарного сопоставления, называемого венгерским алгоритмом. На каждой итерации алгоритм находит наилучшее соответствие между прогнозом и истинными данными (соответствие, которое оптимизирует функцию стоимости, например, среднеквадратичное расстояние между углами ящика, суммированное по всем ящикам). Затем вычисляется потеря между парами «предиктор-основное значение-истина», и ее можно распространить обратно. Завышенные прогнозы (прогнозы без соответствия GT) влекут за собой дискретные потери, которые побуждают их снизить свой уровень уверенности. Этот процесс необходим для повышения точности модели и уменьшения ошибок.
проблема
Временная сложность венгерского алгоритма составляет o(n³). Интересно, что это не обязательно является узким местом в качестве обучения: в работе «Проблема стабильного брака: междисциплинарный обзор с точки зрения физика» (The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective), Fenoaltea et al., 2021, показано, что алгоритм нестабилен, то есть небольшое изменение его целевой функции может привести к значительному изменению результата сопоставления, что приведет к непоследовательным целям обучения запросов. Практические последствия обучения преобразователей заключаются в том, что объектные запросы могут перескакивать между объектами, и требуется много времени, чтобы изучить наилучшие признаки для конвергенции. Другими словами, нестабильность алгоритма приводит к колебаниям в процессе обучения, что требует больше времени для достижения наилучших результатов.
DN-DETR (обнаружение объектов путем устранения шума)
Ли и др. предложил элегантное решение проблемы нестабильного соответствия, которое впоследствии было принято во многих других работах, включая DINO, Mask DINO, Group DETR и другие.
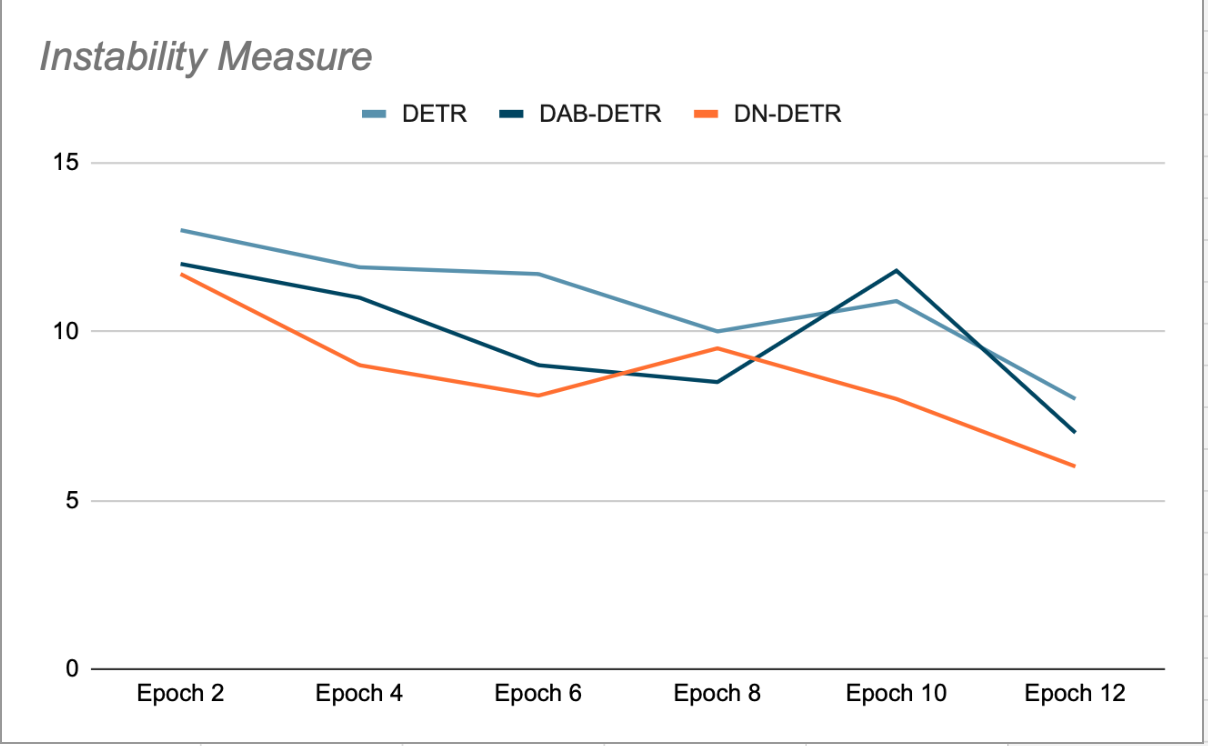
Основная идея DN-DETR — улучшить обучение путем создания Легко наклоняемые воображаемые опорные точкиОн пропускает процесс сопоставления. Это достигается путем добавления небольшого количества шума к тайлам GT (истинной земли) во время обучения и использования этих шумных тайлов в качестве опорных точек для запросов декодера. Запросы DN маскируются от органических запросов и наоборот, чтобы избежать перекрёстного внимания, которое может помешать обучению. Обнаружения, генерируемые этими запросами, уже сопоставлены с исходными тайлами GT и не требуют двудольного сопоставления. Авторы DN-DETR показали, что на этапах проверки в конце каждой эпохи (где удаление шума отключено) это повышает стабильность модели по сравнению с DETR и DAB-DETR, а это означает, что запросы Plus стабильно сопоставляются с объектом GT в последовательных эпохах (см. рисунок 2).
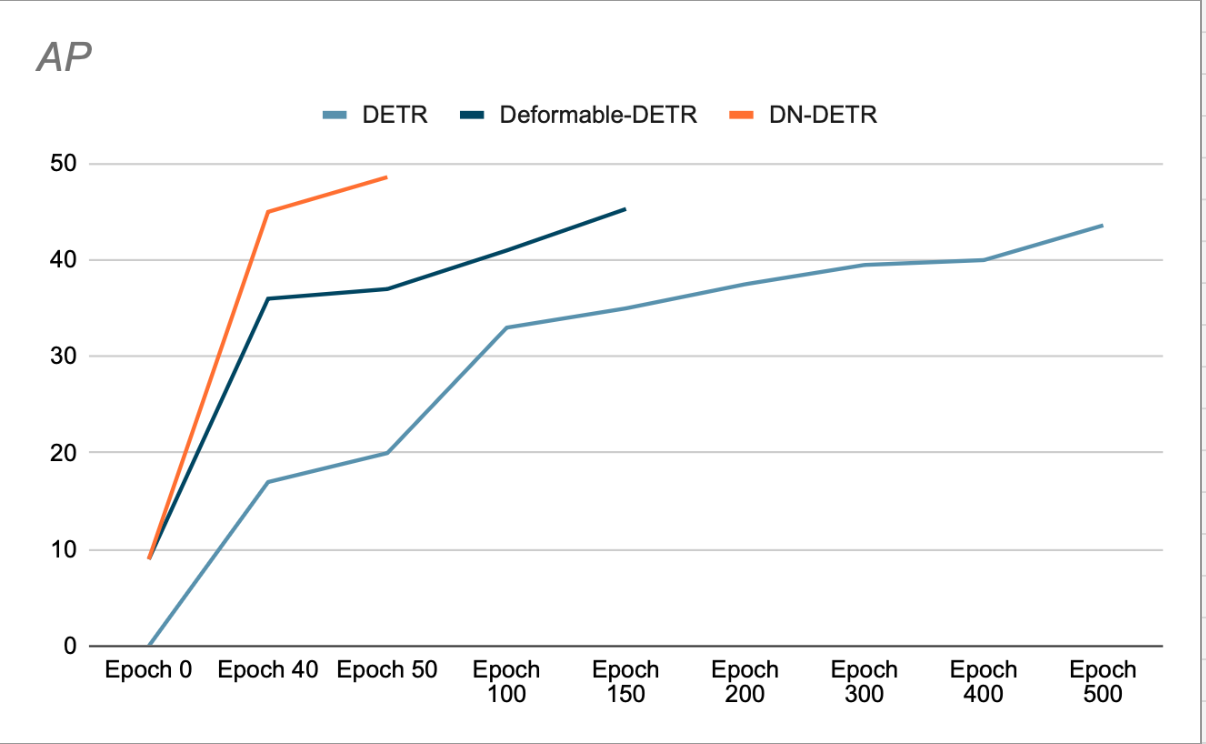
Авторы показывают, что использование DN ускоряет сходимость и позволяет добиться лучших результатов обнаружения. (См. рисунок 3). Их исследование удаления показывает увеличение AP (средней точности) на 1.9% в наборе данных обнаружения COCO по сравнению с предыдущим SOTA (DAB-DETR, AP 42.2%) при использовании ResNet-50 в качестве основы.
Удаление шума DINO и контраста
DINO развил эту идею дальше, добавив контрастное обучение к механизму удаления шума: в дополнение к положительному примеру DINO создает еще одну, зашумленную версию каждого GT, которая математически сконструирована так, чтобы находиться дальше от GT, чем положительный пример (см. рисунок 4). Эта версия используется в качестве отрицательного примера для обучения: модель учится принимать обнаружение, наиболее близкое к истинному значению, и отвергать обнаружение, более удаленное (обучаясь предсказывать класс «нет объекта»).
Кроме того, DINO поддерживает множественную кластеризацию для контрастного шумоподавления (CDN) — несколько шумовых привязок для каждого объекта GT — что позволяет извлечь максимальную пользу из каждой итерации обучения.
Авторы DINO сообщили о средней точности (AP) 49% (по COCO val2017) при использовании CDN.
Современные временные модели, которым необходимо отслеживать объекты от кадра к кадру, такие как Sparse4Dv3, используют сети CDN и добавляют группы временного шумоподавления, в которых некоторые успешные DN-якоря сохраняются (вместе с изученными не-DN-якорями) для использования в последующих кадрах, что повышает производительность модели при отслеживании объектов.

مناقشة
Шумоподавление (DN) улучшает скорость сходимости и конечную производительность детекторов видеотрансформаторов. Однако при рассмотрении развития различных методов, упомянутых выше, возникают следующие вопросы:
- DN улучшает модели, использующие обучаемые якоря. Но действительно ли важны обучаемые якоря? Будет ли DN также улучшать модели, использующие необучаемые якоря?
- Основной вклад DN в обучение заключается в добавлении стабильности процессу градиентного спуска за счет обхода двудольного сопоставления. Однако двоичное сопоставление, по-видимому, существует в первую очередь потому, что нормой в работе преобразователей является избежание пространственных ограничений в запросах. Итак, если мы вручную ограничим запросы определенными местоположениями изображений и откажемся от двоичного сопоставления (или воспользуемся упрощенной версией двоичного сопоставления, которая выполняется для каждого фрагмента изображения отдельно), улучшит ли DN результаты?
Мне не удалось найти работ, которые давали бы четкие ответы на эти вопросы. Моя гипотеза заключается в том, что модель, использующая необучаемые якоря (при условии, что якоря не слишком редки) и пространственно ограниченные запросы, 1) не потребует алгоритма бинарного сопоставления и 2) не получит выгоды от DN при обучении, поскольку якоря уже известны и нет никакого выигрыша в обучении регрессии от других эфемерных якорей.
Если якоря закреплены, но разбросаны, я понимаю, что использование эфемерных якорей облегчает спуск и может обеспечить «теплое» начало тренировочного процесса.
Anchor-DETR (Wand et al., 2021) сравнивает пространственное распределение обучаемых и необучаемых якорей, а также производительность соответствующих моделей. По моему мнению, обучаемость не добавляет особой ценности производительности модели. Стоит отметить, что в обоих методах они используют венгерский алгоритм, поэтому неясно, смогут ли они отказаться от двоичного сопоставления и при этом сохранить производительность.
Следует иметь в виду, что могут быть продуктивные причины избегать использования NMS при выводе, что поощряет использование венгерского алгоритма при обучении.
Где устранение шума может иметь действительно важное значение? По моему мнению - в Прослеживаемость. При отслеживании модель снабжается видеопотоком и должна не только обнаруживать несколько объектов в последовательных кадрах, но и сохранять уникальную идентификацию каждого обнаруженного объекта. Модели временного преобразователя, то есть модели, использующие последовательную природу потоковой передачи видео, не обрабатывают отдельные кадры независимо. Вместо этого он ведет банк, в котором хранятся предыдущие открытия. В процессе обучения модель отслеживания побуждается регрессировать от предыдущего обнаружения объекта (или, точнее, фиксатора, связанного с предыдущим обнаружением объекта), а не просто регрессировать от ближайшего фиксатора. Поскольку предыдущее открытие не ограничивается какой-то фиксированной сетью стабилизаторов, вполне вероятно, что гибкость, стимулируемая DN, полезна. Мне бы очень хотелось прочитать будущие работы, посвященные этим вопросам.
Вот и все об устранении шума и его вкладе в преобразователи зрения! Если вам понравилась моя статья, приглашаю вас посетить некоторые из моих других статей по глубокому обучению и машинному обучению, а также компьютерное зрение!
Комментарии закрыты.