

Я опробовал новую функцию генерации изображений в Gemini, и она просто потрясающая.
Краткое содержание:
- Google запустила собственную функцию создания и редактирования изображений с использованием новой бета-версии Gemini 2.0 Flash.
- Функция уже доступна бесплатно в AI Studio, и вы можете создавать серии скоординированных изображений и редактировать их с помощью простых текстовых команд.
- Вы можете удалять и добавлять элементы, вставлять текст, раскрашивать изображения, создавать визуальные истории и многое другое.
Термин «изначально мультимодальный» в области ИИ мы слышим уже больше года, но до сих пор компании не спешили раскрывать весь мультимодальный потенциал своих моделей ИИ. Google наконец-то выпустила свой последний прототип «Gemini 2.0 Flash Experimental» с… Возможность создания и редактирования оригинальных изображенийой.
Теперь вы, возможно, задаетесь вопросом, в чем важность создания изображений? Генерация изображений на основе ИИ уже некоторое время доступна во всех основных чат-ботах на основе ИИ, таких как ChatGPT. Когда мы генерируем изображения ИИ на ChatGPT или Gemini, они направляются в специализированную модель на основе диффузии, такую как Dall-E 3 или Imagen 3. Эти модели обучаются на изображениях и предназначены только для генерации изображений; Это расширение основной модели ИИ, а не ее часть.
Однако лингвистические модели зрения, такие как Gemini Изначально мультимедийный, то есть он может понимать, генерировать и изменять как текст, так и изображения. До сих пор ни одна технологическая компания не предоставила пользователям такую возможность. OpenAI продемонстрировала свою собственную функцию генерации изображений с помощью GPT-4o в 2024 году, но, опять же, она так и не была выпущена.
 Благодаря функции генерации оригинального изображения вы получите: Лучшая координация Где многомодальные модели обучаются на огромном наборе данных из различных сред. В результате эти модели лучше понимают концепции и демонстрируют более широкие знания о мире.
Благодаря функции генерации оригинального изображения вы получите: Лучшая координация Где многомодальные модели обучаются на огромном наборе данных из различных сред. В результате эти модели лучше понимают концепции и демонстрируют более широкие знания о мире.
Помимо создания изображений, вы можете легко редактировать их, используя простые текстовые команды. Например, вы можете загрузить изображение и попросить модель добавить солнцезащитные очки, вставить жирный текст, удалить объекты и многое другое. В отличие от моделей диффузии, которые заново генерируют всё изображение при каждой новой команде, собственные мультимедийные модели сохраняют согласованность при многократном редактировании.
Создание изображений с помощью демо Gemini 2.0 Flash
В настоящее время функция создания оригинального изображения недоступна для публичных пользователей. Демонстрационная версия Gemini 2.0 Flash с собственной генерацией изображений доступна только на платформе Google AI Studio (زيارة) бесплатно.
После предварительного просмотра модели в AI Studio она в ближайшем будущем будет выпущена в Gemini для всеобщего использования. Однако я опробовал новую модель Gemini с функцией создания изображений, и это был очень захватывающий опыт.
Сначала я начал с визуального руководства, чтобы продемонстрировать последовательность способности Gemini генерировать изображения. Я попросил Gemini создать наглядное руководство по приготовлению омлета, сделав фотографии для каждого этапа процесса.
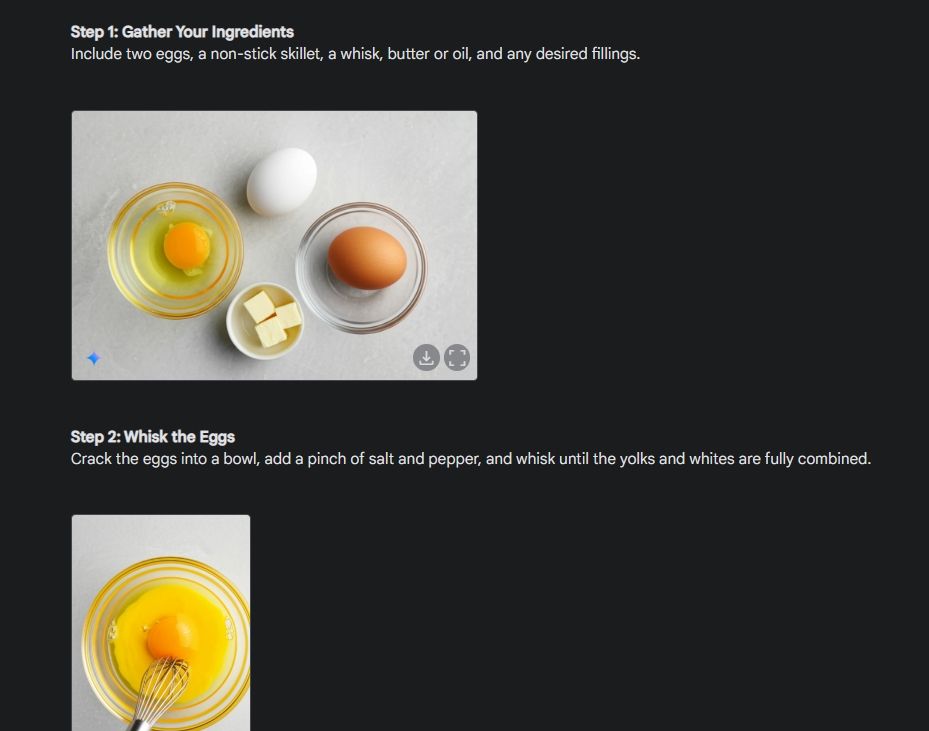
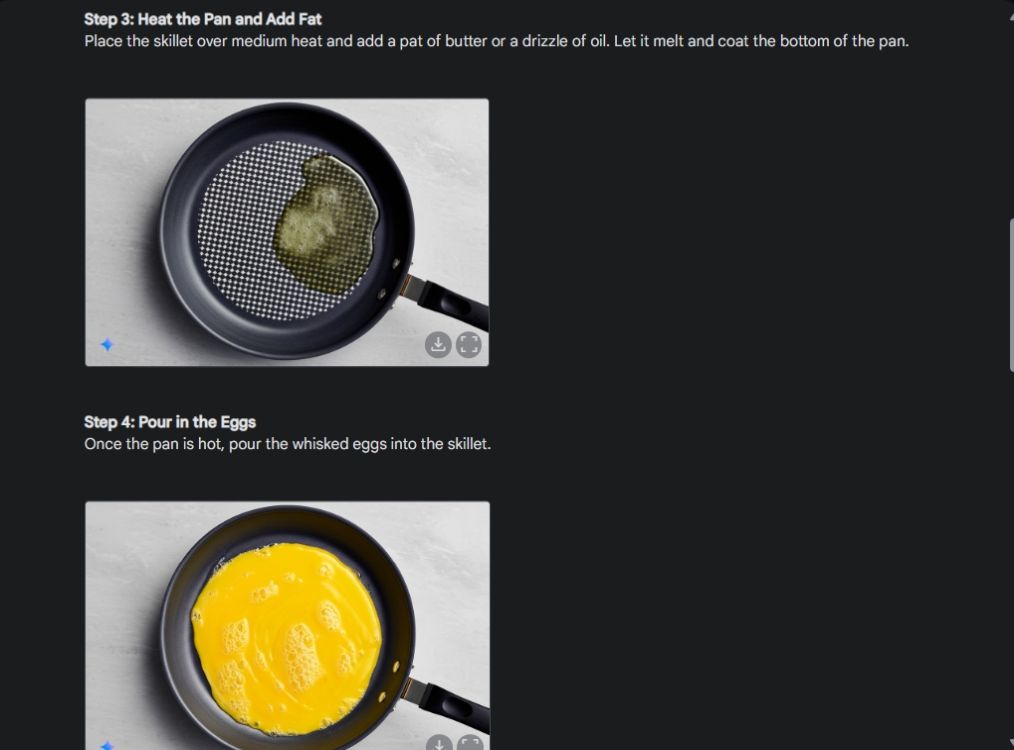

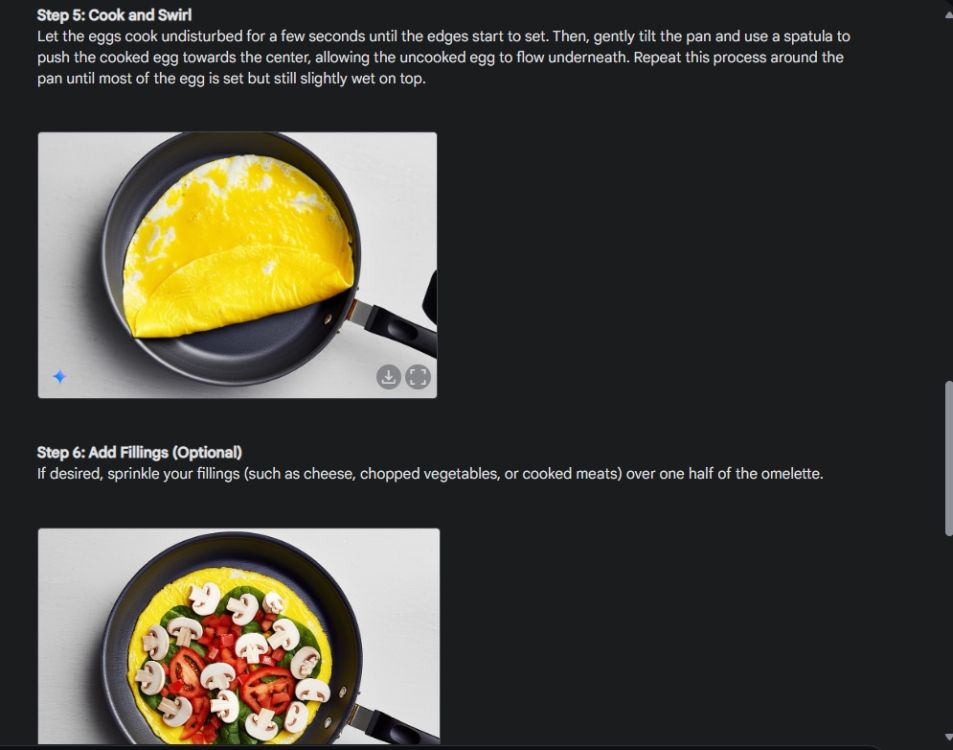
Как вы можете видеть, результаты на всех изображениях очень схожи, без каких-либо ошибок. Даже чаша такая же, как на второй картинке. Наконец, вы можете загружать изображения в разрешении 1024 x 680. Таким образом, вы можете создать визуальное руководство по чему угодно.
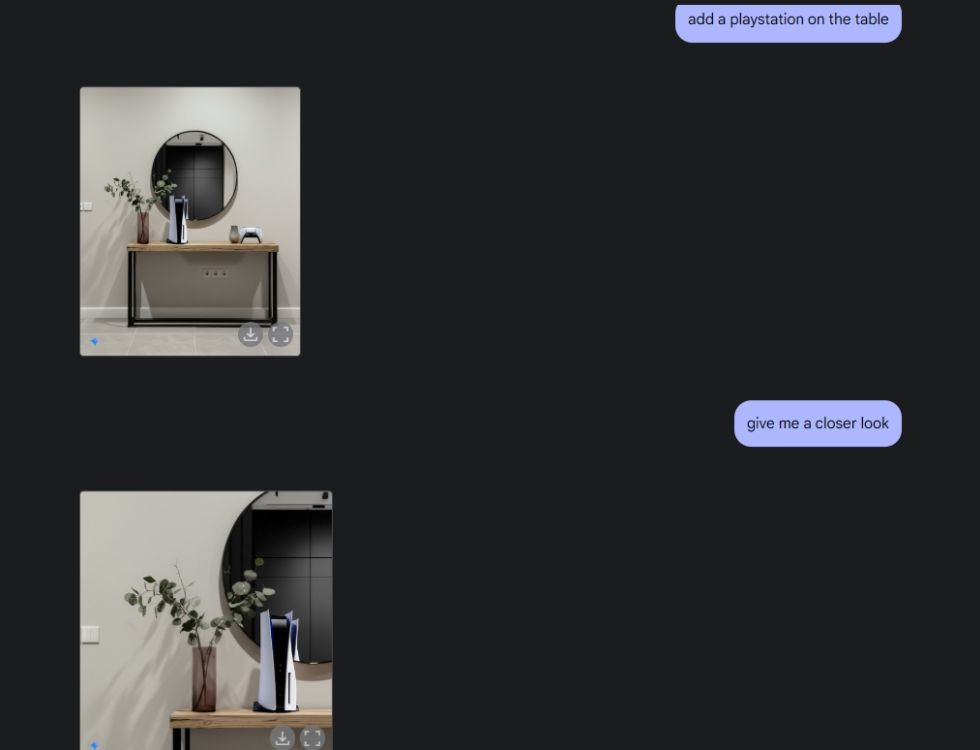
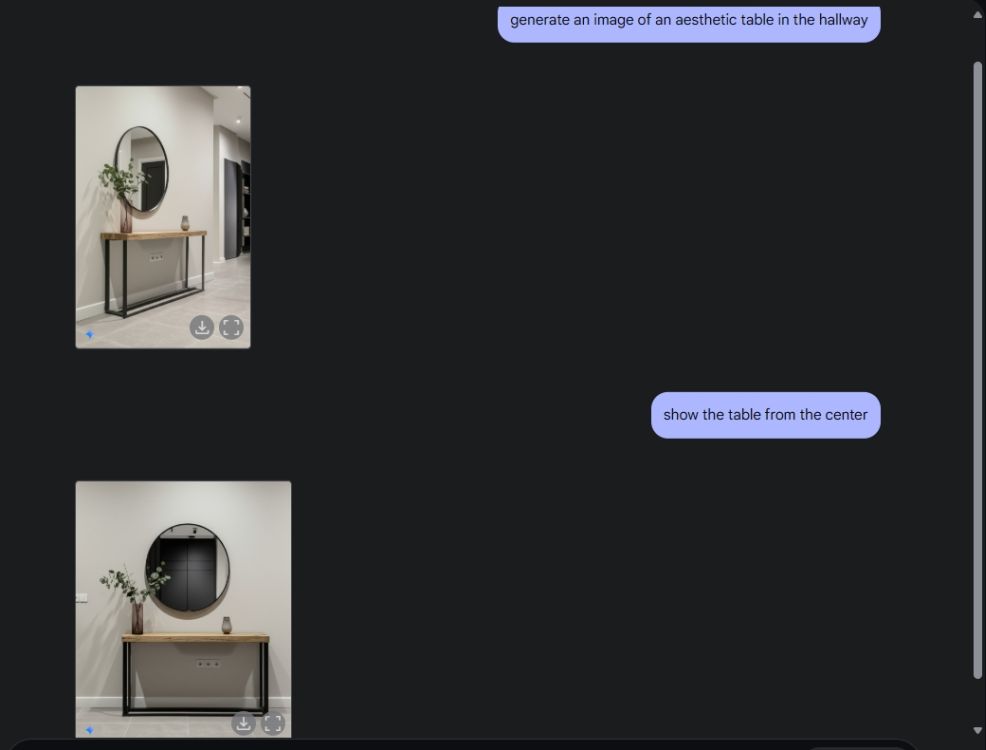
Затем я попросил Gemini создать эстетичное изображение стола, а затем попросил его рассмотреть стол с центрального ракурса камеры. Он проделал идеальную работу. Затем я попросил Gemini добавить PlayStation на стол и рассмотреть ее поближе. И снова Близнецы добились успеха. Как вы можете видеть ниже, модель ИИ также включала отражение PS5 в зеркале позади нее.
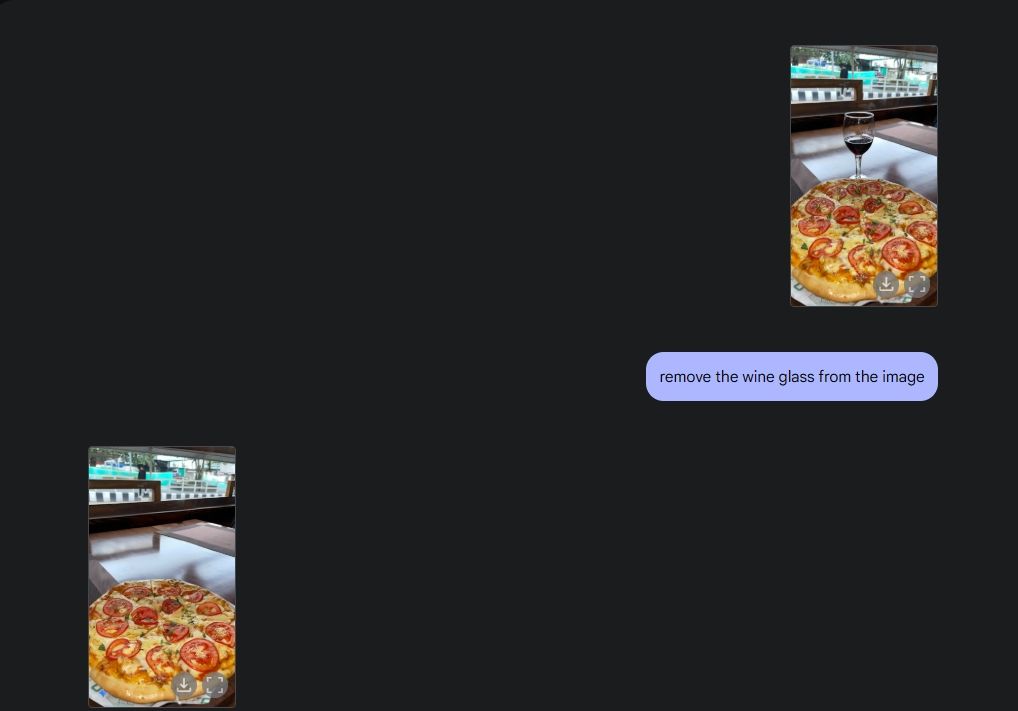
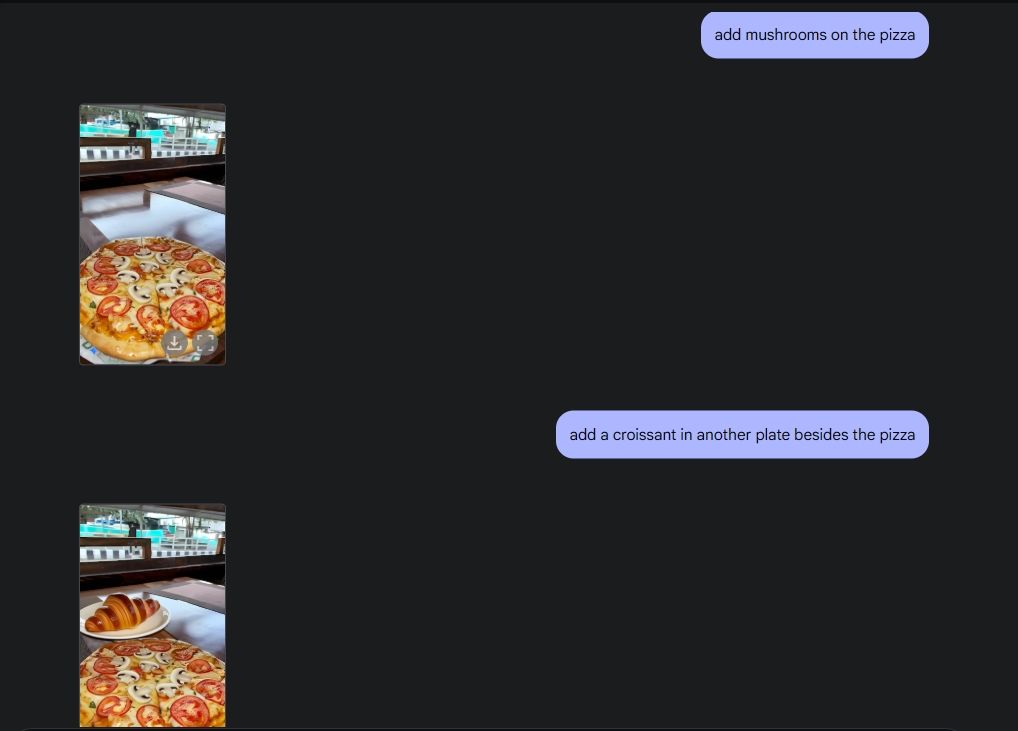
Чтобы продемонстрировать исходную обработку фотографии, я загрузил фотографию из своей галереи и попросил Gemini 2.0 убрать бокал со стола. Затем я попросил Джемини добавить в пиццу грибы, и он справился великолепно. Затем я попросил Gemini добавить круассан, и вот вам решение — редактирование фотографий на базе искусственного интеллекта со всеми его функциями, благодаря мультимедийным возможностям Gemini.
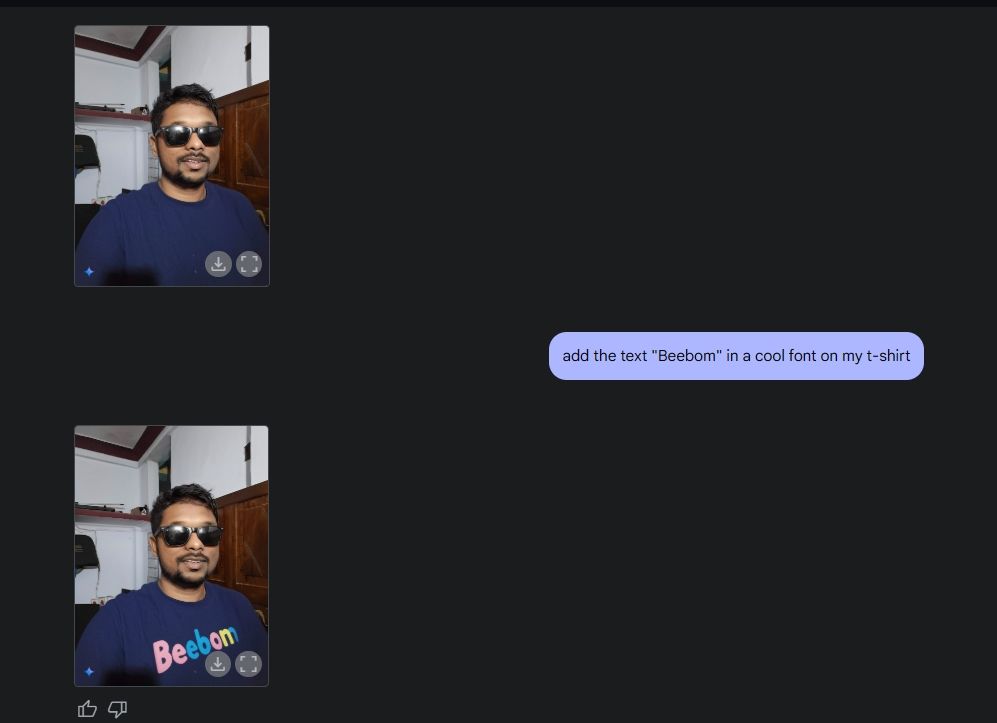
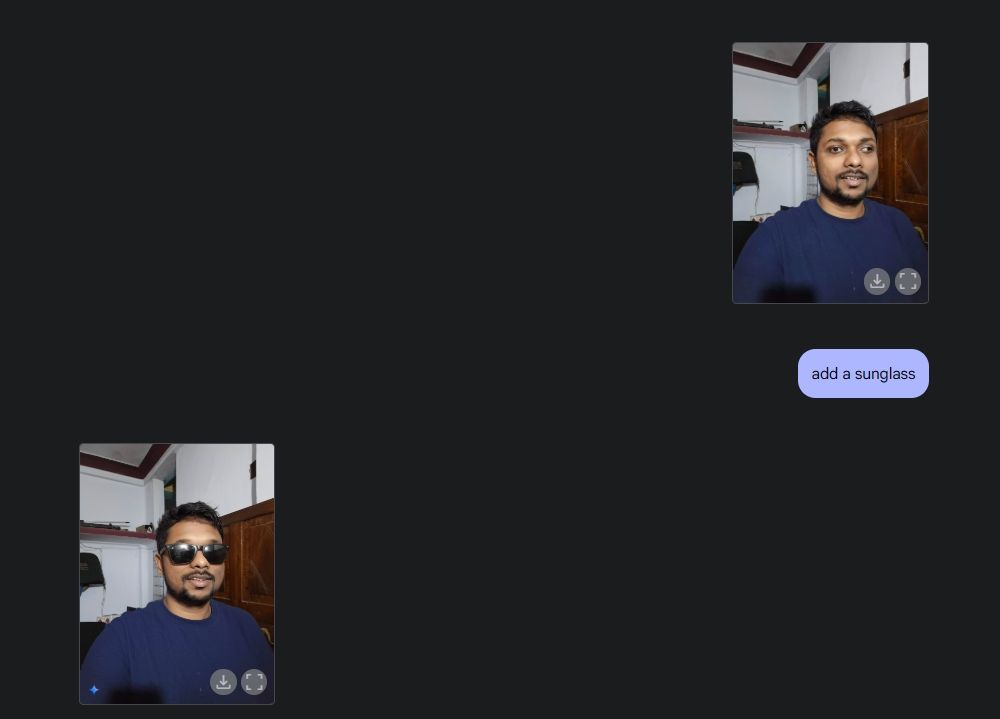
Затем я загрузил свою фотографию, попросил Gemini добавить солнцезащитные очки, а затем добавил текст «Beebom» на свою футболку. Оба были выполнены очень хорошо.
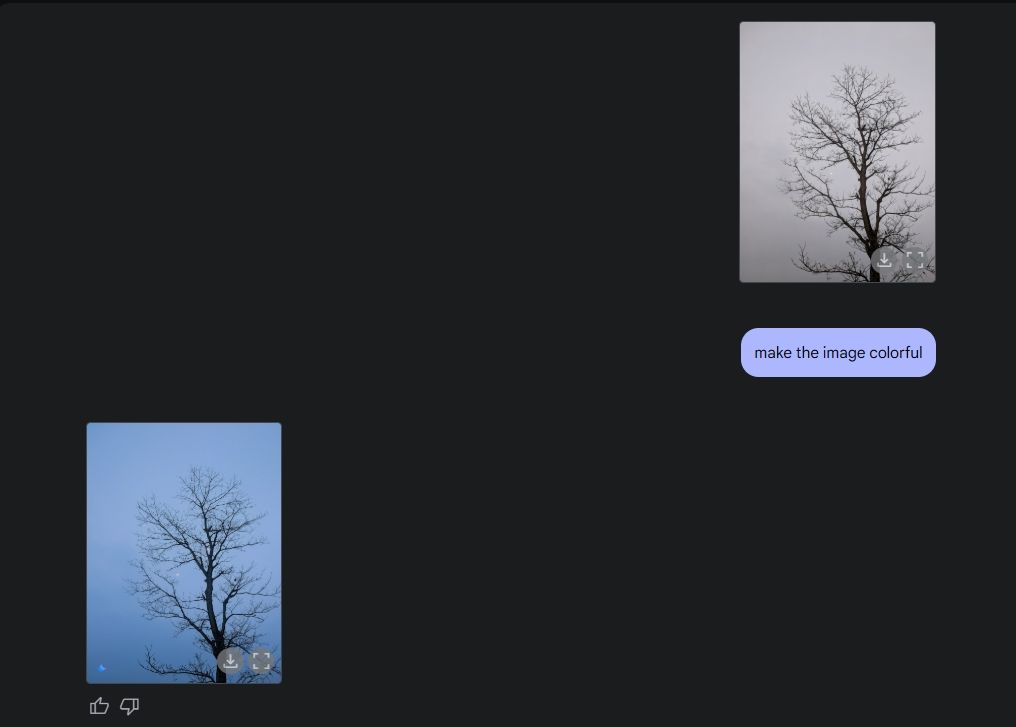
Наконец, я попросила Джемини раскрасить картинку, и он тоже справился с этим хорошо. Я имею в виду, что изображение стало красивее, чем было раньше, без каких-либо странных ошибок, искажений или отсутствия какой-либо части изображения.
Новые мультимедийные возможности Gemini можно использовать во многих ситуациях. Google проделал большую работу по созданию и редактированию собственных изображений, и я планирую использовать его более тщательно в ближайшие недели, чтобы проверить его возможности.
После выпуска Veo 2 для создания видео и Imagen 3 для создания специализированных изображений Google, похоже, превзошла OpenAI во многих областях; Не только в области генерации текста с помощью ИИ. Поэтому будет интересно посмотреть, что OpenAI предпримет, чтобы вернуть себе лидерство с ChatGPT.
Комментарии закрыты.