

Мы наблюдаем бум моделей ИИ. Однако возникает все более серьезная проблема: названия этих моделей становятся все более сложными, образуя лабиринт аббревиатур и технических терминов, которые сбивают с толку даже энтузиастов-пользователей ИИ. Это усложняет процесс поиска и сравнения различных моделей, что влияет на понимание их областей применения и возможностей.

Нам нужны более простые обозначения для моделей ИИ.
Несмотря на всю инновационность каждой новой модели ИИ, их сложные названия представляют собой существенное препятствие для пользователей, пытающихся понять и различить эти модели. Эти сложности не только затрудняют доступ обычного пользователя к этим мощным инструментам, но и создают существенный барьер для понимания и использования их полного потенциала. Модели искусственного интеллекта, машинное обучение, обработка естественного языка — вот некоторые важные термины в этом контексте.
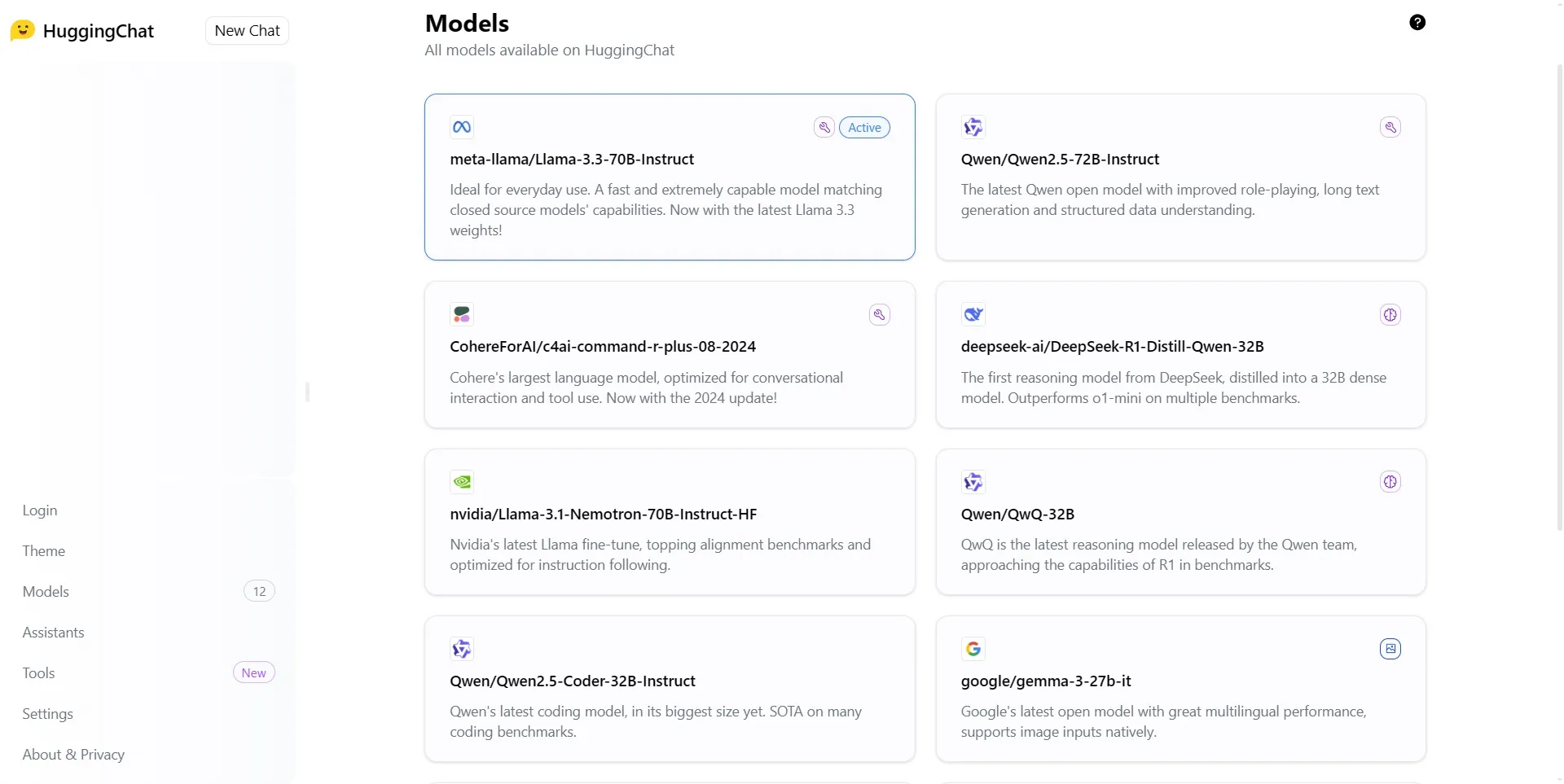
Например, когда китайский технологический гигант Alibaba запустил свою модель Qwen2.5-Coder-32B, кто на самом деле понимал, на что она способна? Чтобы узнать это, приходилось искать специальные термины.
Хотя компании, занимающиеся ИИ, часто выбирают креативное название для своего продукта, например, Gemini, Mistral или Llama, окончательное название модели включает в себя определенные технические атрибуты, такие как номер версии или итерации, архитектура или тип, количество параметров и другие конкретные характеристики. Например, название относится к Лама 2 70B-чат Эта модель от Meta (Llama) представляет собой большую языковую модель с 70 миллиардами (70B) параметров и специально разработана для целей разговора (чата).
По сути, название модели ИИ служит кратким обозначением ее ключевых характеристик, позволяя исследователям и техническим пользователям быстро понять ее природу и назначение, однако для обычного человека оно часто непонятно.
Представьте себе ситуацию, когда пользователь хочет выбрать одну из последних моделей для выполнения определенной задачи. Им доступны такие варианты, как Gemini 2.0 Flash Thinking Experimental, DeepSeek R1 Distill Qwen 14B, Phi-3 Medium 14B и GPT-4o. Не вдаваясь в технические характеристики, различить эти модели становится непростой задачей.
Череда названий моделей, каждое из которых более непонятно, чем предыдущее, подчеркивает необходимость фундаментального изменения способа наименования и представления моделей ИИ. В идеале название модели ИИ должно быть простым, понятным и запоминающимся представлением ее назначения и возможностей.
Представьте себе, если бы автомобили называли в соответствии с техническими характеристиками их двигателей и типами подвески, а не простыми, говорящими о многом названиями, такими как «Mustang» или «Civic». В современных соглашениях об именовании моделей ИИ технические характеристики часто ставятся выше простоты использования. Хотя некоторые термины важны для исследователей, для обычного пользователя они по большей части бессмысленны.
Отрасли необходимо принять более ориентированный на пользователя подход к наименованию. Простые, интуитивно понятные и описательные имена могут значительно улучшить пользовательский опыт.
Более простой способ обнаружить возможности
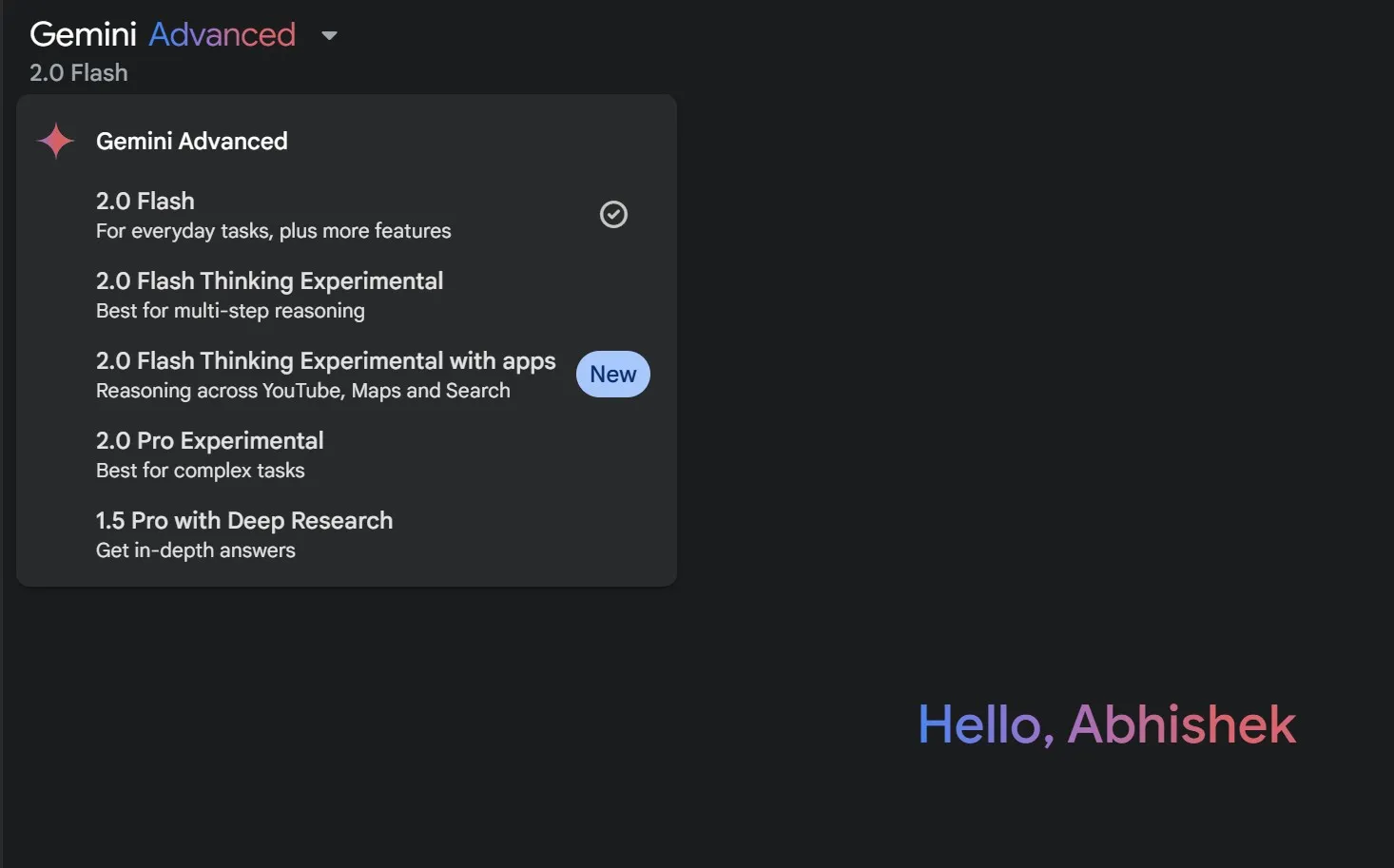
Помимо запутанных названий, еще одной серьезной проблемой является выяснение того, что может делать конкретная модель ИИ. Возможности часто скрыты глубоко в технической документации. Это усугубляется огромным разнообразием моделей и специализированных функций. Простое название само по себе не может отражать весь спектр возможностей модели ИИ. Понимание возможностей моделей ИИ имеет решающее значение для оптимального использования этих передовых технологий.
К счастью, инструменты ИИ, использующие эти модели, добавляют краткое описание для определения варианта использования или его возможностей — например, Google указывает, что модель Близнецы 2.0 Мгновенное мышление Использует передовое мышление при подготовке 2.0 Pro Лучше всего подходит для сложных задач. Это не идеальное решение, но некоторая помощь есть. Это объяснение дает некоторые рекомендации пользователям, но оно все еще ограничено.
Вместо того чтобы полагаться на технические термины, названия моделей должны отражать их основную функцию или возможности. Если сокращения необходимы, их следует выбирать тщательно, чтобы их было легко запомнить и произнести. Кроме того, для обозначения обновлений и улучшений следует использовать четкие и краткие номера версий. Стандартные соглашения об именовании могут упростить процесс выбора модели.
Кроме того, модели ИИ можно классифицировать по названиям, которые отражают их основную функцию или уникальную особенность, например, «чат-бот», «резюматор текста» или «идентификатор изображения». Такая ясность развеяла бы мифы о технологии искусственного интеллекта. Такой подход упростит процесс обнаружения, позволяя вам: Определить модели и инструменты Самый подходящий ИИ для ваших задач быстро Без необходимости продираться через лабиринт непонятных названий и описаний. Это значительно улучшит пользовательский опыт.
Однако большинство языковых моделей обладают разнообразными возможностями и могут выполнять более одной задачи. Поэтому этот подход может оказаться не идеальным для больших, сложных языковых моделей. В частности, большие языковые модели выходят за рамки простых классификаций.

Вы можете быстро выстроить продуктивный рабочий процесс, используя различные инструменты ИИ.
Текущее состояние названий моделей ИИ может сбивать с толку. Переход к более простым наименованиям и улучшенным методам обнаружения может значительно улучшить пользовательский опыт и сделать передовые технологии доступными для всех. Пока этого не произошло, оставаться в курсе событий, использовать ресурсы сообщества и экспериментировать с различными моделями может помочь пользователям ориентироваться в сложном мире ИИ. Благодаря исследованиям и экспериментам пользователи могут эффективно использовать возможности ИИ.
Комментарии закрыты.